A month ago, I blogged about my work to automatically check the
+copyright status of IMDB entries, and try to count the number of
+movies listed in IMDB where it is legal to distribute it the Internet.
+I have continued to look for good data sources, and identified a few
+more. The code used to extract information from various data sources
+is available in
+
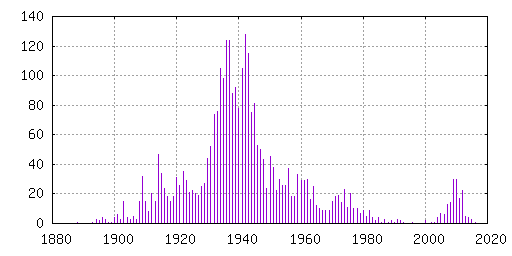
So far I have identified 3186 unique IMDB title IDs. To gain +better understanding of the structure of the data set, I created a +histogram of the year associated with each movie (typically release +year). It is interesting to notice where the peaks and dips in the +graph are located. I wonder why they are placed there. I suspect +World Word II caused the dip around 1940, but what caused the peak +around 2010?
+ +
I've so far identified ten sources for IMDB title IDs for movies in +the public domain or with a free license. This is the statistics +reported when running 'make stats' in the git repository:
+ ++ 249 entries ( 6 unique) with and 288 without IMDB title ID in free-movies-archive-org-butter.json + 2301 entries ( 540 unique) with and 0 without IMDB title ID in free-movies-archive-org-wikidata.json + 830 entries ( 29 unique) with and 0 without IMDB title ID in free-movies-icheckmovies-archive-mochard.json + 2109 entries ( 377 unique) with and 0 without IMDB title ID in free-movies-imdb-pd.json + 291 entries ( 122 unique) with and 0 without IMDB title ID in free-movies-letterboxd-pd.json + 144 entries ( 135 unique) with and 0 without IMDB title ID in free-movies-manual.json + 350 entries ( 1 unique) with and 801 without IMDB title ID in free-movies-publicdomainmovies.json + 4 entries ( 0 unique) with and 124 without IMDB title ID in free-movies-publicdomainreview.json + 698 entries ( 119 unique) with and 118 without IMDB title ID in free-movies-publicdomaintorrents.json + 8 entries ( 8 unique) with and 196 without IMDB title ID in free-movies-vodo.json + 3186 unique IMDB title IDs in total ++ +
The entries without IMDB title ID are candidates to increase the +data set, but might equally well be duplicates of entries already +listed with IMDB title ID in one of the other sources, or represent +movies that lack a IMDB title ID. I've seen examples of all these +situations when peeking at the entries without IMDB title ID. Based +on these data sources, the lower bound for movies listed in IMDB that +are legal to distribute on the Internet is between 3186 and 4713. + +
It would be great for improving the accuracy of this measurement, +if the various sources added IMDB title ID to their metadata. I have +tried to reach the people behind the various sources to ask if they +are interested in doing this, without any positive replies so far. +Perhaps you can help me get in touch with the people behind VODO, +Public Domain Torrents, Public Domain Movies and Public Domain Review +to try to convince them to add more metadata to their movie entries?
+ +Another way you could help is by adding pages to Wikipedia about +movies that are legal to distribute on the Internet. If such page +exist and include a link to both IMDB and The Internet Archive, the +script used to generate free-movies-archive-org-wikidata.json should +pick up the mapping as soon as wikidata is updates.
+