It would be easier to locate the movie you want to watch in the Internet Archive, if the metadata about each movie was more complete and accurate. In the archiving community, a well known saying state that good metadata is a love letter to the future. The metadata in the Internet Archive could use a face lift for the future to love us back. Here is a proposal for a small improvement that would make the metadata more useful today. I've been unable to find any document describing the various standard fields available when uploading videos to the archive, so this proposal is based on my best quess and searching through several of the existing movies.
I have a few use cases in mind. First of all, I would like to be able to count the number of distinct movies in the Internet Archive, without duplicates. I would further like to identify the IMDB title ID of the movies in the Internet Archive, to be able to look up a IMDB title ID and know if I can fetch the video from there and share it with my friends.
Second, I would like the Butter data provider for The Internet archive (available from github), to list as many of the good movies as possible. The plugin currently do a search in the archive with the following parameters:
collection:moviesandfilms AND NOT collection:movie_trailers AND -mediatype:collection AND format:"Archive BitTorrent" AND year
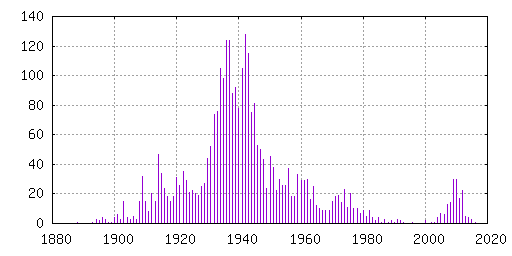
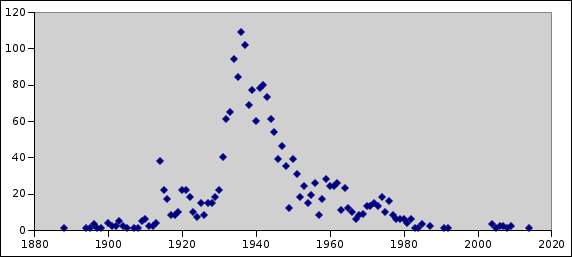
Most of the cool movies that fail to show up in Butter do so because the 'year' field is missing. The 'year' field is populated by the year part from the 'date' field, and should be when the movie was released (date or year). Two such examples are Ben Hur from 1905 and Caminandes 2: Gran Dillama from 2013, where the year metadata field is missing.
So, my proposal is simply, for every movie in The Internet Archive where an IMDB title ID exist, please fill in these metadata fields (note, they can be updated also long after the video was uploaded, but as far as I can tell, only by the uploader):- mediatype
- Should be 'movie' for movies.
- collection
- Should contain 'moviesandfilms'.
- title
- The title of the movie, without the publication year.
- date
- The data or year the movie was released. This make the movie show up in Butter, as well as make it possible to know the age of the movie and is useful to figure out copyright status.
- director
- The director of the movie. This make it easier to know if the correct movie is found in movie databases.
- publisher
- The production company making the movie. Also useful for identifying the correct movie.
- links
- Add a link to the IMDB title page, for example like this: <a href="http://www.imdb.com/title/tt0028496/">Movie in IMDB</a>. This make it easier to find duplicates and allow for counting of number of unique movies in the Archive. Other external references, like to TMDB, could be added like this too.
I did consider proposing a Custom field for the IMDB title ID (for example 'imdb_title_url', 'imdb_code' or simply 'imdb', but suspect it will be easier to simply place it in the links free text field.
I created a list of IMDB title IDs for several thousand movies in the Internet Archive, but I also got a list of several thousand movies without such IMDB title ID (and quite a few duplicates). It would be great if this data set could be integrated into the Internet Archive metadata to be available for everyone in the future, but with the current policy of leaving metadata editing to the uploaders, it will take a while before this happen. If you have uploaded movies into the Internet Archive, you can help. Please consider following my proposal above for your movies, to ensure that movie is properly counted. :)
The list is mostly generated using wikidata, which based on Wikipedia articles make it possible to link between IMDB and movies in the Internet Archive. But there are lots of movies without a Wikipedia article, and some movies where only a collection page exist (like for the Caminandes example above, where there are three movies but only one Wikidata entry).