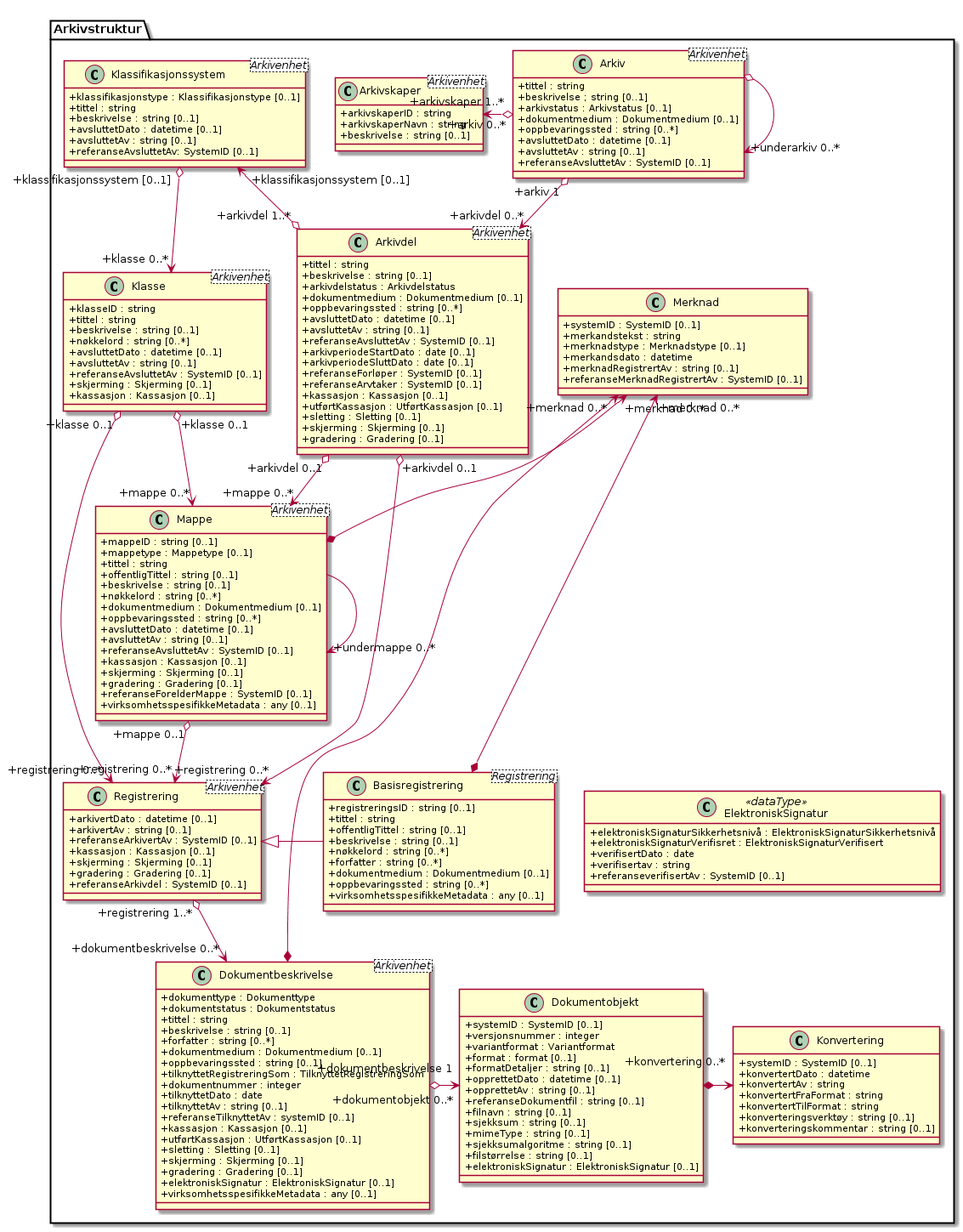
Et virksomhetsarkiv for meg, er et arbeidsverktøy der en enkelt kan
finne informasjonen en trenger når en trenger det, og der
virksomhetens samlede kunnskap er tilgjengelig. Det må være greit å
finne frem i, litt som en bibliotek. Men der et bibliotek gjerne tar
vare på offentliggjort informasjon som er tilgjengelig flere steder,
tar et arkiv vare på virksomhetsintern og til tider personlig
informasjon som ofte kun er tilgjengelig fra et sted.
Jeg mistenker den eneste måten å sikre at arkivet inneholder den
samlede kunnskapen i en virksomhet, er å bruke det som virksomhetens
kunnskapslager. Det innebærer å automatisk kopiere (brev, epost,
SMS-er etc) inn i arkivet når de sendes og mottas, og der filtrere
vekk det en ikke vil ta vare på, og legge på metadata om det som er
samlet inn for enkel gjenfinning. En slik bruk av arkivet innebærer at
arkivet er en del av daglig virke, ikke at det er siste hvilested for
informasjon ingen lenger har daglig bruk for. For å kunne være en del
av det daglige virket må arkivet enkelt kunne integreres med andre
systemer. I disse dager betyr det å tilby arkivet som en
nett-tjeneste til hele virksomheten, tilgjengelig for både mennesker
og datamaskiner. Det betyr i tur å både tilby nettsider og et
maskinlesbart grensesnitt.
For noen år siden erkjente visjonære arkivarer fordelene med et
standardisert maskinlesbart grensesnitt til organisasjonens arkiv. De
gikk igang med å lage noe de kalte
Noark
5 Tjenestegrensesnitt. Gjort riktig, så åpner slike maskinlesbare
grensesnitt for samvirke på tvers av uavhengige programvaresystemer.
Gjort feil, vil det blokkere for samvirke og bidra til
leverandørinnlåsing. For å gjøre det riktig så må grensesnittet være
klart og entydig beskrevet i en spesifikasjon som gjør at
spesifikasjonen tolkes på samme måte uavhengig av hvem som leser den,
og uavhengig av hvem som tar den i bruk.
For å oppnå klare og entydige beskrivelser i en spesifikasjon, som
trengs for å kunne få en fri og åpen standard (se
Digistan-definisjon),
så trengs det en åpen og gjennomsiktig inngangsport med lav terskel,
der de som forsøker å ta den i bruk enkelt kan få inn korreksjoner,
etterlyse klargjøringer og rapportere uklarheter i spesifikasjonen.
En trenger også automatiserte datasystemer som måler og sjekker at et
gitt grensesnitt fungerer i tråd med spesifikasjonen.
For Noark 5 Tjenestegrensesnittet er det nå etablert en slik åpen
og gjennomsiktig inngangsport på prosjekttjenesten github. Denne
inngangsporten består først og fremst av en åpen portal som lar enhver
se hva som er gjort av endringer i spesifikasjonsteksten over tid, men
det hører også med et åpent "diskusjonsforum" der en kan
komme med endringsforslag og forespørsler om klargjøringer. Alle
registrerte brukere på github kan bidra med innspill til disse
henvendelsene.
I samarbeide med Arkivverket har jeg fått opprettet et git-depot
med spesifikasjonsteksten for tjenestegrensesnittet, der det er lagt
inn historikk for endringer i teksten de siste årene, samt lagt inn
endringsforslag og forespørsler om klargjøring av teksten. Bakgrunnen
for at jeg bidro med dette er at jeg er involvert i
Nikita-prosjektet,
som lager en fri programvare-utgave av Noark 5 Tjenestegrensesnitt.
Det er først når en forsøker å lage noe i tråd med en spesifikasjon at
en oppdager hvor mange detaljer som må beskrives i spesifikasjonen for
å sikre samhandling.
Spesifikasjonen vedlikeholdes i et rent tekstformat, for å ha et
format egnet for versjonskontroll via versjontrollsystemet git. Dette
gjør det både enkelt å se konkret hvilke endringer som er gjort når,
samt gjør det praktisk mulig for enhver med github-konto å sende inn
endringsforslag med formuleringer til spesifikasjonsteksten. Dette
tekstformatet vises frem som nettsider på github, slik at en ikke
trenger spesielle verktøy for å se på siste utgave av
spesifikasjonen.
Fra dette rene tekstformatet kan det så avledes ulike formater, som
HTML for websider, PDF for utskrift på papir og ePub for lesing med
ebokleser. Avlednings-systemet (byggesystemet) bruker i dag
verktøyene pandoc, latex, docbook-xsl og GNU make til
transformasjonen. Tekstformatet som brukes dag er
Markdown, men det vurderes
å
endre
til formatet RST i fremtiden for bedre styring av utseende på
PDF-utgaven.
Versjonskontrollsystemet git ble valgt da det er både fleksibelt,
avansert og enkelt å ta i bruk. Github ble valgt (foran f.eks. Gitlab
som vi bruker i Nikita), da Arkivverket allerede hadde tatt i bruk
Github i andre sammenhenger.
Enkle endringer i teksten kan gjøres av priviligerte brukere
direkte i nettsidene til Github, ved å finne aktuell fil som skal
endres (f.eks. kapitler/03-konformitet.md), klikke på den lille
bokstaven i høyre hjørne over teksten. Det kommer opp en nettside der
en kan endre teksten slik en ønsker. Når en er fornøyd med endringen
så må endringen "sjekkes inn" i historikken. Det gjøres ved
å gi en kort beskrivelse av endringen (beskriv helst hvorfor endringen
trengs, ikke hva som er endret), under overskriften "Commit
changes". En kan og bør legge inn en lengre forklaring i det
større skrivefeltet, før en velger om endringen skal sendes direkte
til 'master'-grenen (dvs. autorativ utgave av spesifikasjonen) eller
om en skal lage en ny gren for denne endringen og opprette en
endringsforespørsel (aka "Pull Request"/PR). Når alt dette
er gjort kan en velge "Commit changes" for å sende inn
endringen. Hvis den er lagt inn i "master"-grenen så er den
en offisiell del av spesifikasjonen med en gang. Hvis den derimot er
en endringsforespørsel, så legges den inn i
listen
over forslag til endringer som venter på korrekturlesing og
godkjenning.
Større endringer (for eksempel samtidig endringer i flere filer)
gjøres enklest ved å hente ned en kopi av git-depoet lokalt og gjøre
endringene der før endringsforslaget sendes inn. Denne prosessen er
godt beskrivet i dokumentasjon fra github. Git-prosjektet som skal
"klones" er
https://github.com/arkivverket/noark5-tjenestegrensesnitt-standard/.
For å registrere nye utfordringer (issues) eller kommentere på
eksisterende utfordringer benyttes nettsiden
https://github.com/arkivverket/noark5-tjenestegrensesnitt-standard/issues.
I skrivende stund er det 48 åpne og 11 avsluttede utfordringer. Et
forslag til hva som bør være med når en beskriver en utfordring er
tilgjengelig som utfordring
#14.
For å bygge en PDF-utgave av spesifikasjonen så bruker jeg i dag en
Debian GNU/Linux-maskin med en rekke programpakker installert. Når
dette er på plass, så holder det å kjøre kommandoen 'make pdf html' på
kommandolinjen, vente ca. 20 sekunder, før spesifikasjon.pdf og
spesifikasjon.html ligger klar på disken. Verktøyene for bygging av
PDF, HTML og ePub-utgave er også tilgjengelig på Windows og
MacOSX.
Github bidrar med rammeverket. Men for at åpent vedlikehold av
spesifikasjonen skal fungere, så trengs det folk som bidrar med sin
tid og kunnskap. Arkivverket har sagt de skal bidra med innspill og
godkjenne forslag til endringer, men det blir størst suksess hvis alle
som bruker og lager systemer basert på Noark 5 Tjenestegrensesnitt
bidrar med sin kunnskap og kommer med forslag til forebedringer. Jeg
stiller. Blir du med?
Det er viktig å legge til rette for åpen diskusjon blant alle
interesserte, som ikke krever at en må godta lange kontrakter med
vilkår for deltagelse. Inntil Arkivverket dukker opp på IRC har vi
laget en IRC-kanal der interesserte enkelt kan orientere seg og
diskutere tjenestegrensesnittet. Alle er velkommen til å ta turen
innom
#nikita
(f.eks. via irc.freenode.net) for å møte likesinnede.
Det holder dog ikke å ha en god spesifikasjon, hvis ikke de som tar
den i bruk gjør en like god jobb. For å automatisk teste om et konkret
tjenestegrensesnitt følger (min) forståelse av
spesifikasjonsdokumentet, har jeg skrevet et program som kobler seg
opp til et Noark 5v4 REST-tjeneste og tester alt den finner for å se
om det er i henhold til min tolkning av spesifikasjonen. Dette
verktøyet er tilgjengelig fra
https://github.com/petterreinholdtsen/noark5-tester,
og brukes daglig mens vi utvikler Nikita for å sikre at vi ikke
introduserer nye feil. Hvis en skal sikre samvirke på tvers av ulike
systemer er det helt essensielt å kunne raskt og automatisk sjekke at
tjenestegrensesnittet oppfører seg som forventet. Jeg håper andre som
lager sin utgave av tjenestegrensesnittet vi bruke dette verktøyet,
slik at vi tidlig og raskt kan oppdage hvor vi har tolket
spesifikasjonen ulikt, og dermed få et godt grunnlag for å gjøre
spesifikasjonsteksten enda klarere og bedre.
Dagens beskrivelse av Noark 5 Tjenestegrensesnitt er et svært godt
utgangspunkt for å gjøre virksomhetens arkiv til et dynamisk og
sentralt arbeidsverktøy i organisasjonen. Blir du med å gjøre den
enda bedre?



![[Bilde av Ruters billettautomat med Windows 2000-feilmelding]](http://people.skolelinux.org/pere/blog/images/2019-02-13-ruter-win2000pro.jpeg)