Recently, I needed to automatically check the copyright status of a
set of The Internet Movie database
(IMDB) entries, to figure out which one of the movies they refer
to can be freely distributed on the Internet. This proved to be
harder than it sounds. IMDB for sure list movies without any
copyright protection, where the copyright protection has expired or
where the movie is lisenced using a permissive license like one from
Creative Commons. These are mixed with copyright protected movies,
and there seem to be no way to separate these classes of movies using
the information in IMDB.
First I tried to look up entries manually in IMDB,
Wikipedia and
The Internet Archive, to get a
feel how to do this. It is hard to know for sure using these sources,
but it should be possible to be reasonable confident a movie is "out
of copyright" with a few hours work per movie. As I needed to check
almost 20,000 entries, this approach was not sustainable. I simply
can not work around the clock for about 6 years to check this data
set.
I asked the people behind The Internet Archive if they could
introduce a new metadata field in their metadata XML for IMDB ID, but
was told that they leave it completely to the uploaders to update the
metadata. Some of the metadata entries had IMDB links in the
description, but I found no way to download all metadata files in bulk
to locate those ones and put that approach aside.
In the process I noticed several Wikipedia articles about movies
had links to both IMDB and The Internet Archive, and it occured to me
that I could use the Wikipedia RDF data set to locate entries with
both, to at least get a lower bound on the number of movies on The
Internet Archive with a IMDB ID. This is useful based on the
assumption that movies distributed by The Internet Archive can be
legally distributed on the Internet. With some help from the RDF
community (thank you DanC), I was able to come up with this query to
pass to the SPARQL interface on
Wikidata:
SELECT ?work ?imdb ?ia ?when ?label
WHERE
{
?work wdt:P31/wdt:P279* wd:Q11424.
?work wdt:P345 ?imdb.
?work wdt:P724 ?ia.
OPTIONAL {
?work wdt:P577 ?when.
?work rdfs:label ?label.
FILTER(LANG(?label) = "en").
}
}
If I understand the query right, for every film entry anywhere in
Wikpedia, it will return the IMDB ID and The Internet Archive ID, and
when the movie was released and its English title, if either or both
of the latter two are available. At the moment the result set contain
2338 entries. Of course, it depend on volunteers including both
correct IMDB and The Internet Archive IDs in the wikipedia articles
for the movie. It should be noted that the result will include
duplicates if the movie have entries in several languages. There are
some bogus entries, either because The Internet Archive ID contain a
typo or because the movie is not available from The Internet Archive.
I did not verify the IMDB IDs, as I am unsure how to do that
automatically.
I wrote a small python script to extract the data set from Wikidata
and check if the XML metadata for the movie is available from The
Internet Archive, and after around 1.5 hour it produced a list of 2097
free movies and their IMDB ID. In total, 171 entries in Wikidata lack
the refered Internet Archive entry. I assume the 70 "disappearing"
entries (ie 2338-2097-171) are duplicate entries.
This is not too bad, given that The Internet Archive report to
contain 5331
feature films at the moment, but it also mean more than 3000
movies are missing on Wikipedia or are missing the pair of references
on Wikipedia.
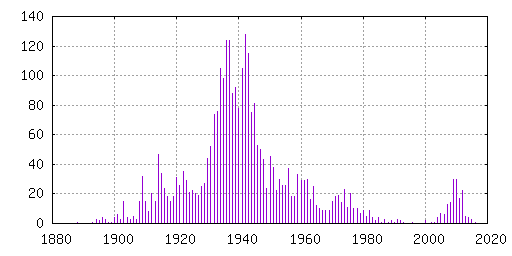
I was curious about the distribution by release year, and made a
little graph to show how the amount of free movies is spread over the
years:
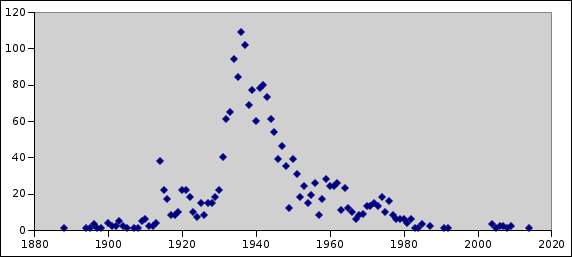
I expect the relative distribution of the remaining 3000 movies to
be similar.
If you want to help, and want to ensure Wikipedia can be used to
cross reference The Internet Archive and The Internet Movie Database,
please make sure entries like this are listed under the "External
links" heading on the Wikipedia article for the movie:
* {{Internet Archive film|id=FightingLady}}
* {{IMDb title|id=0036823|title=The Fighting Lady}}
Please verify the links on the final page, to make sure you did not
introduce a typo.
Here is the complete list, if you want to correct the 171
identified Wikipedia entries with broken links to The Internet
Archive: Q1140317,
Q458656,
Q458656,
Q470560,
Q743340,
Q822580,
Q480696,
Q128761,
Q1307059,
Q1335091,
Q1537166,
Q1438334,
Q1479751,
Q1497200,
Q1498122,
Q865973,
Q834269,
Q841781,
Q841781,
Q1548193,
Q499031,
Q1564769,
Q1585239,
Q1585569,
Q1624236,
Q4796595,
Q4853469,
Q4873046,
Q915016,
Q4660396,
Q4677708,
Q4738449,
Q4756096,
Q4766785,
Q880357,
Q882066,
Q882066,
Q204191,
Q204191,
Q1194170,
Q940014,
Q946863,
Q172837,
Q573077,
Q1219005,
Q1219599,
Q1643798,
Q1656352,
Q1659549,
Q1660007,
Q1698154,
Q1737980,
Q1877284,
Q1199354,
Q1199354,
Q1199451,
Q1211871,
Q1212179,
Q1238382,
Q4906454,
Q320219,
Q1148649,
Q645094,
Q5050350,
Q5166548,
Q2677926,
Q2698139,
Q2707305,
Q2740725,
Q2024780,
Q2117418,
Q2138984,
Q1127992,
Q1058087,
Q1070484,
Q1080080,
Q1090813,
Q1251918,
Q1254110,
Q1257070,
Q1257079,
Q1197410,
Q1198423,
Q706951,
Q723239,
Q2079261,
Q1171364,
Q617858,
Q5166611,
Q5166611,
Q324513,
Q374172,
Q7533269,
Q970386,
Q976849,
Q7458614,
Q5347416,
Q5460005,
Q5463392,
Q3038555,
Q5288458,
Q2346516,
Q5183645,
Q5185497,
Q5216127,
Q5223127,
Q5261159,
Q1300759,
Q5521241,
Q7733434,
Q7736264,
Q7737032,
Q7882671,
Q7719427,
Q7719444,
Q7722575,
Q2629763,
Q2640346,
Q2649671,
Q7703851,
Q7747041,
Q6544949,
Q6672759,
Q2445896,
Q12124891,
Q3127044,
Q2511262,
Q2517672,
Q2543165,
Q426628,
Q426628,
Q12126890,
Q13359969,
Q13359969,
Q2294295,
Q2294295,
Q2559509,
Q2559912,
Q7760469,
Q6703974,
Q4744,
Q7766962,
Q7768516,
Q7769205,
Q7769988,
Q2946945,
Q3212086,
Q3212086,
Q18218448,
Q18218448,
Q18218448,
Q6909175,
Q7405709,
Q7416149,
Q7239952,
Q7317332,
Q7783674,
Q7783704,
Q7857590,
Q3372526,
Q3372642,
Q3372816,
Q3372909,
Q7959649,
Q7977485,
Q7992684,
Q3817966,
Q3821852,
Q3420907,
Q3429733,
Q774474
As usual, if you use Bitcoin and want to show your support of my
activities, please send Bitcoin donations to my address
15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.