I går var jeg i Follo tingrett som sakkyndig vitne og presenterte
mine undersøkelser rundt
telling
av filmverk i det fri, relatert til
foreningen NUUGs involvering i
saken om
Økokrims beslag og senere inndragning av DNS-domenet
popcorn-time.no. Jeg snakket om flere ting, men mest om min
vurdering av hvordan filmbransjen har målt hvor ulovlig Popcorn Time
er. Filmbransjens måling er så vidt jeg kan se videreformidlet uten
endringer av norsk politi, og domstolene har lagt målingen til grunn
når de har vurdert Popcorn Time både i Norge og i utlandet (tallet
99% er referert også i utenlandske domsavgjørelser).
I forkant av mitt vitnemål skrev jeg et notat, mest til meg selv,
med de punktene jeg ønsket å få frem. Her er en kopi av notatet jeg
skrev og ga til aktoratet. Merkelig nok ville ikke dommerene ha
notatet, så hvis jeg forsto rettsprosessen riktig ble kun
histogram-grafen lagt inn i dokumentasjonen i saken. Dommerne var
visst bare interessert i å forholde seg til det jeg sa i retten,
ikke det jeg hadde skrevet i forkant. Uansett så antar jeg at flere
enn meg kan ha glede av teksten, og publiserer den derfor her.
Legger ved avskrift av dokument 09,13, som er det sentrale
dokumentet jeg kommenterer.
Kommentarer til «Evaluation of (il)legality» for Popcorn
Time
Oppsummering
Målemetoden som Økokrim har lagt til grunn når de påstår at 99% av
filmene tilgjengelig fra Popcorn Time deles ulovlig har
svakheter.
De eller den som har vurdert hvorvidt filmer kan lovlig deles har
ikke lyktes med å identifisere filmer som kan deles lovlig og har
tilsynelatende antatt at kun veldig gamle filmer kan deles lovlig.
Økokrim legger til grunn at det bare finnes èn film, Charlie
Chaplin-filmen «The Circus» fra 1928, som kan deles fritt blant de
som ble observert tilgjengelig via ulike Popcorn Time-varianter.
Jeg finner tre flere blant de observerte filmene: «The Brain That
Wouldn't Die» fra 1962, «God’s Little Acre» fra 1958 og «She Wore a
Yellow Ribbon» fra 1949. Det er godt mulig det finnes flere. Det
finnes dermed minst fire ganger så mange filmer som lovlig kan deles
på Internett i datasettet Økokrim har lagt til grunn når det påstås
at mindre enn 1 % kan deles lovlig.
Dernest, utplukket som gjøres ved søk på tilfeldige ord hentet fra
ordlisten til Dale-Chall avviker fra årsfordelingen til de brukte
filmkatalogene som helhet, hvilket påvirker fordelingen mellom
filmer som kan lovlig deles og filmer som ikke kan lovlig deles. I
tillegg gir valg av øvre del (de fem første) av søkeresultatene et
avvik fra riktig årsfordeling, hvilket påvirker fordelingen av verk
i det fri i søkeresultatet.
Det som måles er ikke (u)lovligheten knyttet til bruken av Popcorn
Time, men (u)lovligheten til innholdet i bittorrent-filmkataloger
som vedlikeholdes uavhengig av Popcorn Time.
Omtalte dokumenter: 09,12, 09,13, 09,14,
09,18, 09,19, 09,20.
Utfyllende kommentarer
Økokrim har forklart domstolene at minst 99% av alt som er
tilgjengelig fra ulike Popcorn Time-varianter deles ulovlig på
Internet. Jeg ble nysgjerrig på hvordan de er kommet frem til dette
tallet, og dette notatet er en samling kommentarer rundt målingen
Økokrim henviser til. Litt av bakgrunnen for at jeg valgte å se på
saken er at jeg er interessert i å identifisere og telle hvor mange
kunstneriske verk som er falt i det fri eller av andre grunner kan
lovlig deles på Internett, og dermed var interessert i hvordan en
hadde funnet den ene prosenten som kanskje deles lovlig.
Andelen på 99% kommer fra et ukreditert og udatert notatet som tar
mål av seg å dokumentere en metode for å måle hvor (u)lovlig ulike
Popcorn Time-varianter er.
Raskt oppsummert, så forteller metodedokumentet at på grunn av at
det ikke er mulig å få tak i komplett liste over alle filmtitler
tilgjengelig via Popcorn Time, så lages noe som skal være et
representativt utvalg ved å velge 50 søkeord større enn tre tegn fra
ordlisten kjent som Dale-Chall. For hvert søkeord gjøres et søk og
de første fem filmene i søkeresultatet samles inn inntil 100 unike
filmtitler er funnet. Hvis 50 søkeord ikke var tilstrekkelig for å
nå 100 unike filmtitler ble flere filmer fra hvert søkeresultat lagt
til. Hvis dette heller ikke var tilstrekkelig, så ble det hentet ut
og søkt på flere tilfeldig valgte søkeord inntil 100 unike
filmtitler var identifisert.
Deretter ble for hver av filmtitlene «vurdert hvorvidt det var
rimelig å forvente om at verket var vernet av copyright, ved å se på
om filmen var tilgjengelig i IMDB, samt se på regissør,
utgivelsesår, når det var utgitt for bestemte markedsområder samt
hvilke produksjons- og distribusjonsselskap som var registrert» (min
oversettelse).
Metoden er gjengitt både i de ukrediterte dokumentene 09,13 og
09,19, samt beskrevet fra side 47 i dokument 09,20, lysark datert
2017-02-01. Sistnevnte er kreditert Geerart Bourlon fra Motion
Picture Association EMEA. Metoden virker å ha flere svakheter som
gir resultatene en slagside. Den starter med å slå fast at det ikke
er mulig å hente ut en komplett liste over alle filmtitler som er
tilgjengelig, og at dette er bakgrunnen for metodevalget. Denne
forutsetningen er ikke i tråd med det som står i dokument 09,12, som
ikke heller har oppgitt forfatter og dato. Dokument 09,12 forteller
hvordan hele kataloginnholdet ble lasted ned og talt opp. Dokument
09,12 er muligens samme rapport som ble referert til i dom fra Oslo
Tingrett 2017-11-03
(sak
17-093347TVI-OTIR/05) som rapport av 1. juni 2017 av Alexander
Kind Petersen, men jeg har ikke sammenlignet dokumentene ord for ord
for å kontrollere dette.
IMDB er en forkortelse for The Internet Movie Database, en
anerkjent kommersiell nettjeneste som brukes aktivt av både
filmbransjen og andre til å holde rede på hvilke spillefilmer (og
endel andre filmer) som finnes eller er under produksjon, og
informasjon om disse filmene. Datakvaliteten er høy, med få feil og
få filmer som mangler. IMDB viser ikke informasjon om
opphavsrettslig status for filmene på infosiden for hver film. Som
del av IMDB-tjenesten finnes det lister med filmer laget av
frivillige som lister opp det som antas å være verk i det fri.
Det finnes flere kilder som kan brukes til å finne filmer som er
allemannseie (public domain) eller har bruksvilkår som gjør det
lovlig for alleå dele dem på Internett. Jeg har de siste ukene
forsøkt å samle og krysskoble disse listene for å forsøke å telle
antall filmer i det fri. Ved å ta utgangspunkt i slike lister (og
publiserte filmer for Internett-arkivets del), har jeg så langt
klart å identifisere over 11 000 filmer, hovedsaklig spillefilmer.
De aller fleste oppføringene er hentet fra IMDB selv, basert på det
faktum at alle filmer laget i USA før 1923 er falt i det fri.
Tilsvarende tidsgrense for Storbritannia er 1912-07-01, men dette
utgjør bare veldig liten del av spillefilmene i IMDB (19 totalt).
En annen stor andel kommer fra Internett-arkivet, der jeg har
identifisert filmer med referanse til IMDB. Internett-arkivet, som
holder til i USA, har som
policy å kun publisere
filmer som det er lovlig å distribuere. Jeg har under arbeidet
kommet over flere filmer som har blitt fjernet fra
Internett-arkivet, hvilket gjør at jeg konkluderer med at folkene
som kontrollerer Internett-arkivet har et aktivt forhold til å kun
ha lovlig innhold der, selv om det i stor grad er drevet av
frivillige. En annen stor liste med filmer kommer fra det
kommersielle selskapet Retro Film Vault, som selger allemannseide
filmer til TV- og filmbransjen, Jeg har også benyttet meg av lister
over filmer som hevdes å være allemannseie, det være seg Public
Domain Review, Public Domain Torrents og Public Domain Movies (.net
og .info), samt lister over filmer med Creative Commons-lisensiering
fra Wikipedia, VODO og The Hill Productions. Jeg har gjort endel
stikkontroll ved å vurdere filmer som kun omtales på en liste. Der
jeg har funnet feil som har gjort meg i tvil om vurderingen til de
som har laget listen har jeg forkastet listen fullstendig (gjelder
en liste fra IMDB).
Ved å ta utgangspunkt i verk som kan antas å være lovlig delt på
Internett (fra blant annet Internett-arkivet, Public Domain
Torrents, Public Domain Reivew og Public Domain Movies), og knytte
dem til oppføringer i IMDB, så har jeg så langt klart å identifisere
over 11 000 filmer (hovedsaklig spillefilmer) det er grunn til å tro
kan lovlig distribueres av alle på Internett. Som ekstra kilder er
det brukt lister over filmer som antas/påstås å være allemannseie.
Disse kildene kommer fra miljøer som jobber for å gjøre tilgjengelig
for almennheten alle verk som er falt i det fri eller har
bruksvilkår som tillater deling.
I tillegg til de over 11 000 filmene der tittel-ID i IMDB er
identifisert, har jeg funnet mer enn 20 000 oppføringer der jeg ennå
ikke har hatt kapasitet til å spore opp tittel-ID i IMDB. Noen av
disse er nok duplikater av de IMDB-oppføringene som er identifisert
så langt, men neppe alle. Retro Film Vault hevder å ha 44 000
filmverk i det fri i sin katalog, så det er mulig at det reelle
tallet er betydelig høyere enn de jeg har klart å identifisere så
langt. Konklusjonen er at tallet 11 000 er nedre grense for hvor
mange filmer i IMDB som kan lovlig deles på Internett. I følge statistikk fra IMDB er det 4.6
millioner titler registrert, hvorav 3 millioner er TV-serieepisoder.
Jeg har ikke funnet ut hvordan de fordeler seg per år.
Hvis en fordeler på år alle tittel-IDene i IMDB som hevdes å lovlig
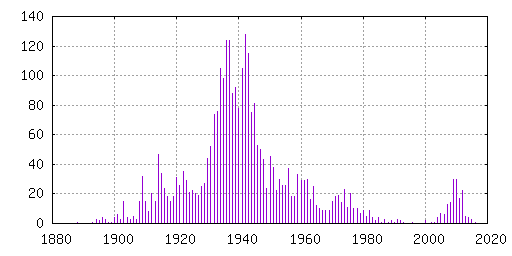
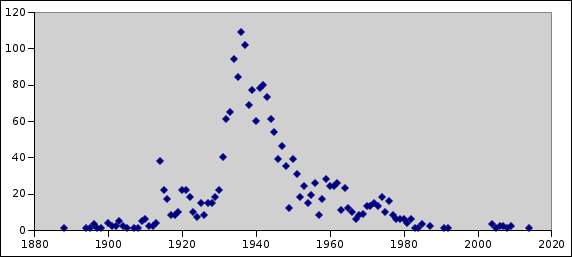
kunne deles på Internett, får en følgende histogram:

En kan i histogrammet se at effekten av manglende registrering
eller fornying av registrering er at mange filmer gitt ut i USA før
1978 er allemannseie i dag. I tillegg kan en se at det finnes flere
filmer gitt ut de siste årene med bruksvilkår som tillater deling,
muligens på grunn av fremveksten av
Creative
Commons-bevegelsen..
For maskinell analyse av katalogene har jeg laget et lite program
som kobler seg til bittorrent-katalogene som brukes av ulike Popcorn
Time-varianter og laster ned komplett liste over filmer i
katalogene, noe som bekrefter at det er mulig å hente ned komplett
liste med alle filmtitler som er tilgjengelig. Jeg har sett på fire
bittorrent-kataloger. Den ene brukes av klienten tilgjengelig fra
www.popcorntime.sh og er navngitt 'sh' i dette dokumentet. Den
andre brukes i følge dokument 09,12 av klienten tilgjengelig fra
popcorntime.ag og popcorntime.sh og er navngitt 'yts' i dette
dokumentet. Den tredje brukes av websidene tilgjengelig fra
popcorntime-online.tv og er navngitt 'apidomain' i dette dokumentet.
Den fjerde brukes av klienten tilgjenglig fra popcorn-time.to i
følge dokument 09,12, og er navngitt 'ukrfnlge' i dette
dokumentet.
Metoden Økokrim legger til grunn skriver i sitt punkt fire at
skjønn er en egnet metode for å finne ut om en film kan lovlig deles
på Internett eller ikke, og sier at det ble «vurdert hvorvidt det
var rimelig å forvente om at verket var vernet av copyright». For
det første er det ikke nok å slå fast om en film er «vernet av
copyright» for å vite om det er lovlig å dele den på Internett eller
ikke, da det finnes flere filmer med opphavsrettslige bruksvilkår
som tillater deling på Internett. Eksempler på dette er Creative
Commons-lisensierte filmer som Citizenfour fra 2014 og Sintel fra
2010. I tillegg til slike finnes det flere filmer som nå er
allemannseie (public domain) på grunn av manglende registrering
eller fornying av registrering selv om både regisør,
produksjonsselskap og distributør ønsker seg vern. Eksempler på
dette er Plan 9 from Outer Space fra 1959 og Night of the Living
Dead fra 1968. Alle filmer fra USA som var allemannseie før
1989-03-01 forble i det fri da Bern-konvensjonen, som tok effekt i
USA på det tidspunktet, ikke ble gitt tilbakevirkende kraft. Hvis
det er noe
historien
om sangen «Happy birthday» forteller oss, der betaling for bruk
har vært krevd inn i flere tiår selv om sangen ikke egentlig var
vernet av åndsverksloven, så er det at hvert enkelt verk må vurderes
nøye og i detalj før en kan slå fast om verket er allemannseie eller
ikke, det holder ikke å tro på selverklærte rettighetshavere. Flere
eksempel på verk i det fri som feilklassifiseres som vernet er fra
dokument 09,18, som lister opp søkeresultater for klienten omtalt
som popcorntime.sh og i følge notatet kun inneholder en film (The
Circus fra 1928) som under tvil kan antas å være allemannseie.
Ved rask gjennomlesning av dokument 09,18, som inneholder
skjermbilder fra bruk av en Popcorn Time-variant, fant jeg omtalt
både filmen «The Brain That Wouldn't Die» fra 1962 som er
tilgjengelig
fra Internett-arkivet og som
i
følge Wikipedia er allemannseie i USA da den ble gitt ut i
1962 uten 'copyright'-merking, og filmen «God’s Little Acre» fra
1958 som
er lagt ut på Wikipedia, der det fortelles at
sort/hvit-utgaven er allemannseie. Det fremgår ikke fra dokument
09,18 om filmen omtalt der er sort/hvit-utgaven. Av
kapasitetsårsaker og på grunn av at filmoversikten i dokument 09,18
ikke er maskinlesbart har jeg ikke forsøkt å sjekke alle filmene som
listes opp der om mot liste med filmer som er antatt lovlig kan
distribueres på Internet.
Ved maskinell gjennomgang av listen med IMDB-referanser under
regnearkfanen 'Unique titles' i dokument 09.14, fant jeg i tillegg
filmen «She Wore a Yellow Ribbon» fra 1949) som nok også er
feilklassifisert. Filmen «She Wore a Yellow Ribbon» er tilgjengelig
fra Internett-arkivet og markert som allemannseie der. Det virker
dermed å være minst fire ganger så mange filmer som kan lovlig deles
på Internett enn det som er lagt til grunn når en påstår at minst
99% av innholdet er ulovlig. Jeg ser ikke bort fra at nærmere
undersøkelser kan avdekke flere. Poenget er uansett at metodens
punkt om «rimelig å forvente om at verket var vernet av copyright»
gjør metoden upålitelig.
Den omtalte målemetoden velger ut tilfeldige søketermer fra
ordlisten Dale-Chall. Den ordlisten inneholder 3000 enkle engelske
som fjerdeklassinger i USA er forventet å forstå. Det fremgår ikke
hvorfor akkurat denne ordlisten er valgt, og det er uklart for meg
om den er egnet til å få et representativt utvalg av filmer. Mange
av ordene gir tomt søkeresultat. Ved å simulerte tilsvarende søk
ser jeg store avvik fra fordelingen i katalogen for enkeltmålinger.
Dette antyder at enkeltmålinger av 100 filmer slik målemetoden
beskriver er gjort, ikke er velegnet til å finne andel ulovlig
innhold i bittorrent-katalogene.
En kan motvirke dette store avviket for enkeltmålinger ved å gjøre
mange søk og slå sammen resultatet. Jeg har testet ved å
gjennomføre 100 enkeltmålinger (dvs. måling av (100x100=) 10 000
tilfeldig valgte filmer) som gir mindre, men fortsatt betydelig
avvik, i forhold til telling av filmer pr år i hele katalogen.
Målemetoden henter ut de fem øverste i søkeresultatet.
Søkeresultatene er sortert på antall bittorrent-klienter registrert
som delere i katalogene, hvilket kan gi en slagside mot hvilke
filmer som er populære blant de som bruker bittorrent-katalogene,
uten at det forteller noe om hvilket innhold som er tilgjengelig
eller hvilket innhold som deles med Popcorn Time-klienter. Jeg har
forsøkt å måle hvor stor en slik slagside eventuelt er ved å
sammenligne fordelingen hvis en tar de 5 nederste i søkeresultatet i
stedet. Avviket for disse to metodene for endel kataloger er godt
synlig på histogramet. Her er histogram over filmer funnet i den
komplette katalogen (grønn strek), og filmer funnet ved søk etter
ord i Dale-Chall. Grafer merket 'top' henter fra de 5 første i
søkeresultatet, mens de merket 'bottom' henter fra de 5 siste. En
kan her se at resultatene påvirkes betydelig av hvorvidt en ser på
de første eller de siste filmene i et søketreff.
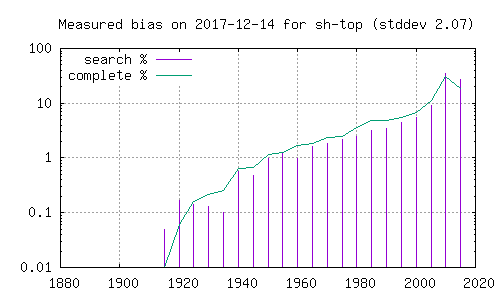

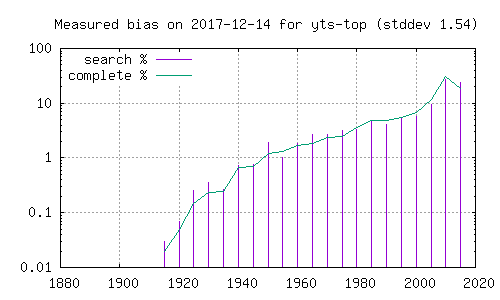

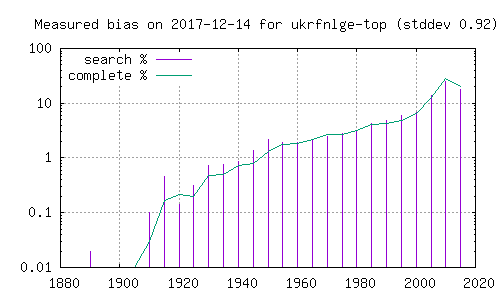

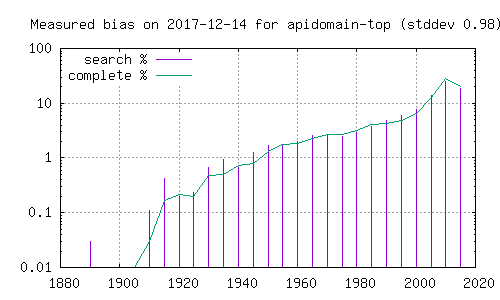

Det er verdt å bemerke at de omtalte bittorrent-katalogene ikke er
laget for bruk med Popcorn Time. Eksempelvis tilhører katalogen
YTS, som brukes av klientet som ble lastes ned fra popcorntime.sh,
et selvstendig fildelings-relatert nettsted YTS.AG med et separat
brukermiljø. Målemetoden foreslått av Økokrim måler dermed ikke
(u)lovligheten rundt bruken av Popcorn Time, men (u)lovligheten til
innholdet i disse katalogene.
Metoden fra Økokrims dokument 09,13 i straffesaken
om DNS-beslag.
1. Evaluation of (il)legality
1.1. Methodology
Due to its technical configuration, Popcorn Time applications don't
allow to make a full list of all titles made available. In order to
evaluate the level of illegal operation of PCT, the following
methodology was applied:
- A random selection of 50 keywords, greater than 3 letters, was
made from the Dale-Chall list that contains 3000 simple English
words1. The selection was made by using a Random Number
Generator2.
- For each keyword, starting with the first randomly selected
keyword, a search query was conducted in the movie section of the
respective Popcorn Time application. For each keyword, the first
five results were added to the title list until the number of 100
unique titles was reached (duplicates were removed).
- For one fork, .CH, insufficient titles were generated via this
approach to reach 100 titles. This was solved by adding any
additional query results above five for each of the 50 keywords.
Since this still was not enough, another 42 random keywords were
selected to finally reach 100 titles.
- It was verified whether or not there is a reasonable expectation
that the work is copyrighted by checking if they are available on
IMDb, also verifying the director, the year when the title was
released, the release date for a certain market, the production
company/ies of the title and the distribution company/ies.
1.2. Results
Between 6 and 9 June 2016, four forks of Popcorn Time were
investigated: popcorn-time.to, popcorntime.ag, popcorntime.sh and
popcorntime.ch. An excel sheet with the results is included in
Appendix 1. Screenshots were secured in separate Appendixes for each
respective fork, see Appendix 2-5.
For each fork, out of 100, de-duplicated titles it was possible to
retrieve data according to the parameters set out above that indicate
that the title is commercially available. Per fork, there was 1 title
that presumably falls within the public domain, i.e. the 1928 movie
"The Circus" by and with Charles Chaplin.
Based on the above it is reasonable to assume that 99% of the movie
content of each fork is copyright protected and is made available
illegally.
This exercise was not repeated for TV series, but considering that
besides production companies and distribution companies also
broadcasters may have relevant rights, it is reasonable to assume that
at least a similar level of infringement will be established.
Based on the above it is reasonable to assume that 99% of all the
content of each fork is copyright protected and are made available
illegally.