I går var jeg i Follo tingrett som sakkyndig vitne og presenterte
- mine undersøkelser rundt
- telling
- av filmverk i det fri, relatert til
- foreningen NUUGs involvering i
- saken om
- Ãkokrims beslag og senere inndragning av DNS-domenet
- popcorn-time.no. Jeg snakket om flere ting, men mest om min
- vurdering av hvordan filmbransjen har målt hvor ulovlig Popcorn Time
- er. Filmbransjens måling er så vidt jeg kan se videreformidlet uten
- endringer av norsk politi, og domstolene har lagt målingen til grunn
- når de har vurdert Popcorn Time både i Norge og i utlandet (tallet
- 99% er referert også i utenlandske domsavgjørelser).
-
-
I forkant av mitt vitnemål skrev jeg et notat, mest til meg selv,
- med de punktene jeg ønsket å få frem. Her er en kopi av notatet jeg
- skrev og ga til aktoratet. Merkelig nok ville ikke dommerene ha
- notatet, så hvis jeg forsto rettsprosessen riktig ble kun
- histogram-grafen lagt inn i dokumentasjonen i saken. Dommerne var
- visst bare interessert i å forholde seg til det jeg sa i retten,
- ikke det jeg hadde skrevet i forkant. Uansett så antar jeg at flere
- enn meg kan ha glede av teksten, og publiserer den derfor her.
- Legger ved avskrift av dokument 09,13, som er det sentrale
- dokumentet jeg kommenterer.
-
-
Kommentarer til «Evaluation of (il)legality» for Popcorn
- Time
-
-
Oppsummering
-
-
MÃ¥lemetoden som Ãkokrim har lagt til grunn nÃ¥r de pÃ¥stÃ¥r at 99% av
- filmene tilgjengelig fra Popcorn Time deles ulovlig har
- svakheter.
-
-
De eller den som har vurdert hvorvidt filmer kan lovlig deles har
- ikke lyktes med å identifisere filmer som kan deles lovlig og har
- tilsynelatende antatt at kun veldig gamle filmer kan deles lovlig.
- Ãkokrim legger til grunn at det bare finnes èn film, Charlie
- Chaplin-filmen «The Circus» fra 1928, som kan deles fritt blant de
- som ble observert tilgjengelig via ulike Popcorn Time-varianter.
- Jeg finner tre flere blant de observerte filmene: «The Brain That
- Wouldn't Die» fra 1962, «Godâs Little Acre» fra 1958 og «She Wore a
- Yellow Ribbon» fra 1949. Det er godt mulig det finnes flere. Det
- finnes dermed minst fire ganger så mange filmer som lovlig kan deles
- pÃ¥ Internett i datasettet Ãkokrim har lagt til grunn nÃ¥r det pÃ¥stÃ¥s
- at mindre enn 1 % kan deles lovlig.
-
-
Dernest, utplukket som gjøres ved søk på tilfeldige ord hentet fra
- ordlisten til Dale-Chall avviker fra årsfordelingen til de brukte
- filmkatalogene som helhet, hvilket påvirker fordelingen mellom
- filmer som kan lovlig deles og filmer som ikke kan lovlig deles. I
- tillegg gir valg av øvre del (de fem første) av søkeresultatene et
- avvik fra riktig årsfordeling, hvilket påvirker fordelingen av verk
- i det fri i søkeresultatet.
-
-
Det som måles er ikke (u)lovligheten knyttet til bruken av Popcorn
- Time, men (u)lovligheten til innholdet i bittorrent-filmkataloger
- som vedlikeholdes uavhengig av Popcorn Time.
-
-
Omtalte dokumenter: 09,12, 09,13, 09,14,
-09,18, 09,19, 09,20.
-
-
Utfyllende kommentarer
-
-
Ãkokrim har forklart domstolene at minst 99% av alt som er
- tilgjengelig fra ulike Popcorn Time-varianter deles ulovlig på
- Internet. Jeg ble nysgjerrig på hvordan de er kommet frem til dette
- tallet, og dette notatet er en samling kommentarer rundt målingen
- Ãkokrim henviser til. Litt av bakgrunnen for at jeg valgte Ã¥ se pÃ¥
- saken er at jeg er interessert i å identifisere og telle hvor mange
- kunstneriske verk som er falt i det fri eller av andre grunner kan
- lovlig deles på Internett, og dermed var interessert i hvordan en
- hadde funnet den ene prosenten som kanskje deles lovlig.
-
-
Andelen på 99% kommer fra et ukreditert og udatert notatet som tar
- mål av seg å dokumentere en metode for å måle hvor (u)lovlig ulike
- Popcorn Time-varianter er.
-
-
Raskt oppsummert, så forteller metodedokumentet at på grunn av at
- det ikke er mulig å få tak i komplett liste over alle filmtitler
- tilgjengelig via Popcorn Time, så lages noe som skal være et
- representativt utvalg ved å velge 50 søkeord større enn tre tegn fra
- ordlisten kjent som Dale-Chall. For hvert søkeord gjøres et søk og
- de første fem filmene i søkeresultatet samles inn inntil 100 unike
- filmtitler er funnet. Hvis 50 søkeord ikke var tilstrekkelig for å
- nå 100 unike filmtitler ble flere filmer fra hvert søkeresultat lagt
- til. Hvis dette heller ikke var tilstrekkelig, så ble det hentet ut
- og søkt på flere tilfeldig valgte søkeord inntil 100 unike
- filmtitler var identifisert.
-
-
Deretter ble for hver av filmtitlene «vurdert hvorvidt det var
- rimelig å forvente om at verket var vernet av copyright, ved å se på
- om filmen var tilgjengelig i IMDB, samt se på regissør,
- utgivelsesår, når det var utgitt for bestemte markedsområder samt
- hvilke produksjons- og distribusjonsselskap som var registrert» (min
- oversettelse).
-
-
Metoden er gjengitt både i de ukrediterte dokumentene 09,13 og
- 09,19, samt beskrevet fra side 47 i dokument 09,20, lysark datert
- 2017-02-01. Sistnevnte er kreditert Geerart Bourlon fra Motion
- Picture Association EMEA. Metoden virker å ha flere svakheter som
- gir resultatene en slagside. Den starter med å slå fast at det ikke
- er mulig å hente ut en komplett liste over alle filmtitler som er
- tilgjengelig, og at dette er bakgrunnen for metodevalget. Denne
- forutsetningen er ikke i tråd med det som står i dokument 09,12, som
- ikke heller har oppgitt forfatter og dato. Dokument 09,12 forteller
- hvordan hele kataloginnholdet ble lasted ned og talt opp. Dokument
- 09,12 er muligens samme rapport som ble referert til i dom fra Oslo
- Tingrett 2017-11-03
- (sak
- 17-093347TVI-OTIR/05) som rapport av 1. juni 2017 av Alexander
- Kind Petersen, men jeg har ikke sammenlignet dokumentene ord for ord
- for å kontrollere dette.
-
-
IMDB er en forkortelse for The Internet Movie Database, en
- anerkjent kommersiell nettjeneste som brukes aktivt av både
- filmbransjen og andre til å holde rede på hvilke spillefilmer (og
- endel andre filmer) som finnes eller er under produksjon, og
- informasjon om disse filmene. Datakvaliteten er høy, med få feil og
- få filmer som mangler. IMDB viser ikke informasjon om
- opphavsrettslig status for filmene på infosiden for hver film. Som
- del av IMDB-tjenesten finnes det lister med filmer laget av
- frivillige som lister opp det som antas å være verk i det fri.
-
-
Det finnes flere kilder som kan brukes til å finne filmer som er
- allemannseie (public domain) eller har bruksvilkår som gjør det
- lovlig for alleå dele dem på Internett. Jeg har de siste ukene
- forsøkt å samle og krysskoble disse listene for å forsøke å telle
- antall filmer i det fri. Ved å ta utgangspunkt i slike lister (og
- publiserte filmer for Internett-arkivets del), har jeg så langt
- klart å identifisere over 11 000 filmer, hovedsaklig spillefilmer.
-
-
De aller fleste oppføringene er hentet fra IMDB selv, basert på det
- faktum at alle filmer laget i USA før 1923 er falt i det fri.
- Tilsvarende tidsgrense for Storbritannia er 1912-07-01, men dette
- utgjør bare veldig liten del av spillefilmene i IMDB (19 totalt).
- En annen stor andel kommer fra Internett-arkivet, der jeg har
- identifisert filmer med referanse til IMDB. Internett-arkivet, som
- holder til i USA, har som
- policy å kun publisere
- filmer som det er lovlig å distribuere. Jeg har under arbeidet
- kommet over flere filmer som har blitt fjernet fra
- Internett-arkivet, hvilket gjør at jeg konkluderer med at folkene
- som kontrollerer Internett-arkivet har et aktivt forhold til å kun
- ha lovlig innhold der, selv om det i stor grad er drevet av
- frivillige. En annen stor liste med filmer kommer fra det
- kommersielle selskapet Retro Film Vault, som selger allemannseide
- filmer til TV- og filmbransjen, Jeg har også benyttet meg av lister
- over filmer som hevdes å være allemannseie, det være seg Public
- Domain Review, Public Domain Torrents og Public Domain Movies (.net
- og .info), samt lister over filmer med Creative Commons-lisensiering
- fra Wikipedia, VODO og The Hill Productions. Jeg har gjort endel
- stikkontroll ved å vurdere filmer som kun omtales på en liste. Der
- jeg har funnet feil som har gjort meg i tvil om vurderingen til de
- som har laget listen har jeg forkastet listen fullstendig (gjelder
- en liste fra IMDB).
-
-
Ved å ta utgangspunkt i verk som kan antas å være lovlig delt på
- Internett (fra blant annet Internett-arkivet, Public Domain
- Torrents, Public Domain Reivew og Public Domain Movies), og knytte
- dem til oppføringer i IMDB, så har jeg så langt klart å identifisere
- over 11 000 filmer (hovedsaklig spillefilmer) det er grunn til å tro
- kan lovlig distribueres av alle på Internett. Som ekstra kilder er
- det brukt lister over filmer som antas/påstås å være allemannseie.
- Disse kildene kommer fra miljøer som jobber for å gjøre tilgjengelig
- for almennheten alle verk som er falt i det fri eller har
- bruksvilkår som tillater deling.
-
-
I tillegg til de over 11 000 filmene der tittel-ID i IMDB er
- identifisert, har jeg funnet mer enn 20 000 oppføringer der jeg ennå
- ikke har hatt kapasitet til å spore opp tittel-ID i IMDB. Noen av
- disse er nok duplikater av de IMDB-oppføringene som er identifisert
- så langt, men neppe alle. Retro Film Vault hevder å ha 44 000
- filmverk i det fri i sin katalog, så det er mulig at det reelle
- tallet er betydelig høyere enn de jeg har klart å identifisere så
- langt. Konklusjonen er at tallet 11 000 er nedre grense for hvor
- mange filmer i IMDB som kan lovlig deles på Internett. I følge statistikk fra IMDB er det 4.6
- millioner titler registrert, hvorav 3 millioner er TV-serieepisoder.
- Jeg har ikke funnet ut hvordan de fordeler seg per år.
-
-
Hvis en fordeler på år alle tittel-IDene i IMDB som hevdes å lovlig
- kunne deles på Internett, får en følgende histogram:
-
-

-
-
En kan i histogrammet se at effekten av manglende registrering
- eller fornying av registrering er at mange filmer gitt ut i USA før
- 1978 er allemannseie i dag. I tillegg kan en se at det finnes flere
- filmer gitt ut de siste årene med bruksvilkår som tillater deling,
- muligens på grunn av fremveksten av
- Creative
- Commons-bevegelsen..
-
-
For maskinell analyse av katalogene har jeg laget et lite program
- som kobler seg til bittorrent-katalogene som brukes av ulike Popcorn
- Time-varianter og laster ned komplett liste over filmer i
- katalogene, noe som bekrefter at det er mulig å hente ned komplett
- liste med alle filmtitler som er tilgjengelig. Jeg har sett på fire
- bittorrent-kataloger. Den ene brukes av klienten tilgjengelig fra
- www.popcorntime.sh og er navngitt 'sh' i dette dokumentet. Den
- andre brukes i følge dokument 09,12 av klienten tilgjengelig fra
- popcorntime.ag og popcorntime.sh og er navngitt 'yts' i dette
- dokumentet. Den tredje brukes av websidene tilgjengelig fra
- popcorntime-online.tv og er navngitt 'apidomain' i dette dokumentet.
- Den fjerde brukes av klienten tilgjenglig fra popcorn-time.to i
- følge dokument 09,12, og er navngitt 'ukrfnlge' i dette
- dokumentet.
-
-
Metoden Ãkokrim legger til grunn skriver i sitt punkt fire at
- skjønn er en egnet metode for å finne ut om en film kan lovlig deles
- på Internett eller ikke, og sier at det ble «vurdert hvorvidt det
- var rimelig å forvente om at verket var vernet av copyright». For
- det første er det ikke nok å slå fast om en film er «vernet av
- copyright» for å vite om det er lovlig å dele den på Internett eller
- ikke, da det finnes flere filmer med opphavsrettslige bruksvilkår
- som tillater deling på Internett. Eksempler på dette er Creative
- Commons-lisensierte filmer som Citizenfour fra 2014 og Sintel fra
- 2010. I tillegg til slike finnes det flere filmer som nå er
- allemannseie (public domain) på grunn av manglende registrering
- eller fornying av registrering selv om både regisør,
- produksjonsselskap og distributør ønsker seg vern. Eksempler på
- dette er Plan 9 from Outer Space fra 1959 og Night of the Living
- Dead fra 1968. Alle filmer fra USA som var allemannseie før
- 1989-03-01 forble i det fri da Bern-konvensjonen, som tok effekt i
- USA på det tidspunktet, ikke ble gitt tilbakevirkende kraft. Hvis
- det er noe
- historien
- om sangen «Happy birthday» forteller oss, der betaling for bruk
- har vært krevd inn i flere tiår selv om sangen ikke egentlig var
- vernet av åndsverksloven, så er det at hvert enkelt verk må vurderes
- nøye og i detalj før en kan slå fast om verket er allemannseie eller
- ikke, det holder ikke å tro på selverklærte rettighetshavere. Flere
- eksempel på verk i det fri som feilklassifiseres som vernet er fra
- dokument 09,18, som lister opp søkeresultater for klienten omtalt
- som popcorntime.sh og i følge notatet kun inneholder en film (The
- Circus fra 1928) som under tvil kan antas å være allemannseie.
-
-
Ved rask gjennomlesning av dokument 09,18, som inneholder
- skjermbilder fra bruk av en Popcorn Time-variant, fant jeg omtalt
- både filmen «The Brain That Wouldn't Die» fra 1962 som er
- tilgjengelig
- fra Internett-arkivet og som
- i
- følge Wikipedia er allemannseie i USA da den ble gitt ut i
- 1962 uten 'copyright'-merking, og filmen «Godâs Little Acre» fra
- 1958 som
- er lagt ut på Wikipedia, der det fortelles at
- sort/hvit-utgaven er allemannseie. Det fremgår ikke fra dokument
- 09,18 om filmen omtalt der er sort/hvit-utgaven. Av
- kapasitetsårsaker og på grunn av at filmoversikten i dokument 09,18
- ikke er maskinlesbart har jeg ikke forsøkt å sjekke alle filmene som
- listes opp der om mot liste med filmer som er antatt lovlig kan
- distribueres på Internet.
-
-
Ved maskinell gjennomgang av listen med IMDB-referanser under
- regnearkfanen 'Unique titles' i dokument 09.14, fant jeg i tillegg
- filmen «She Wore a Yellow Ribbon» fra 1949) som nok også er
- feilklassifisert. Filmen «She Wore a Yellow Ribbon» er tilgjengelig
- fra Internett-arkivet og markert som allemannseie der. Det virker
- dermed å være minst fire ganger så mange filmer som kan lovlig deles
- på Internett enn det som er lagt til grunn når en påstår at minst
- 99% av innholdet er ulovlig. Jeg ser ikke bort fra at nærmere
- undersøkelser kan avdekke flere. Poenget er uansett at metodens
- punkt om «rimelig å forvente om at verket var vernet av copyright»
- gjør metoden upålitelig.
-
-
Den omtalte målemetoden velger ut tilfeldige søketermer fra
- ordlisten Dale-Chall. Den ordlisten inneholder 3000 enkle engelske
- som fjerdeklassinger i USA er forventet å forstå. Det fremgår ikke
- hvorfor akkurat denne ordlisten er valgt, og det er uklart for meg
- om den er egnet til å få et representativt utvalg av filmer. Mange
- av ordene gir tomt søkeresultat. Ved å simulerte tilsvarende søk
- ser jeg store avvik fra fordelingen i katalogen for enkeltmålinger.
- Dette antyder at enkeltmålinger av 100 filmer slik målemetoden
- beskriver er gjort, ikke er velegnet til å finne andel ulovlig
- innhold i bittorrent-katalogene.
-
-
En kan motvirke dette store avviket for enkeltmålinger ved å gjøre
- mange søk og slå sammen resultatet. Jeg har testet ved å
- gjennomføre 100 enkeltmålinger (dvs. måling av (100x100=) 10 000
- tilfeldig valgte filmer) som gir mindre, men fortsatt betydelig
- avvik, i forhold til telling av filmer pr år i hele katalogen.
-
-
Målemetoden henter ut de fem øverste i søkeresultatet.
- Søkeresultatene er sortert på antall bittorrent-klienter registrert
- som delere i katalogene, hvilket kan gi en slagside mot hvilke
- filmer som er populære blant de som bruker bittorrent-katalogene,
- uten at det forteller noe om hvilket innhold som er tilgjengelig
- eller hvilket innhold som deles med Popcorn Time-klienter. Jeg har
- forsøkt å måle hvor stor en slik slagside eventuelt er ved å
- sammenligne fordelingen hvis en tar de 5 nederste i søkeresultatet i
- stedet. Avviket for disse to metodene for endel kataloger er godt
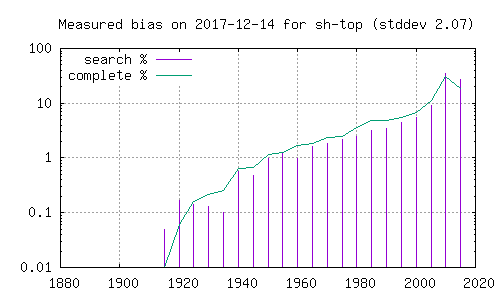
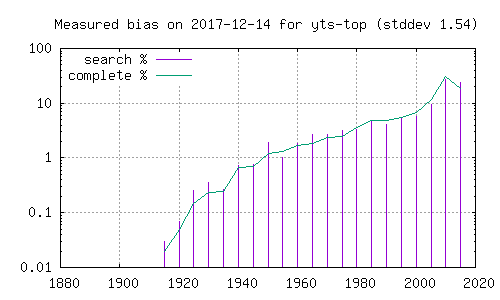
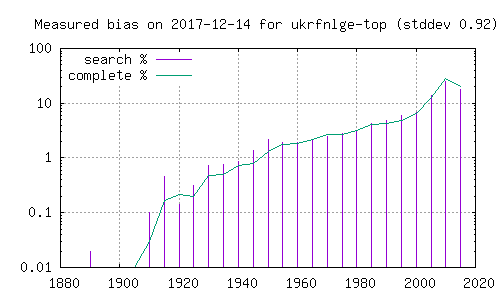
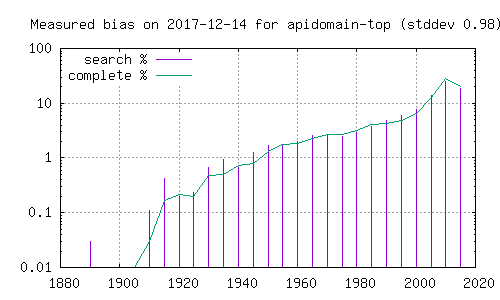
- synlig på histogramet. Her er histogram over filmer funnet i den
- komplette katalogen (grønn strek), og filmer funnet ved søk etter
- ord i Dale-Chall. Grafer merket 'top' henter fra de 5 første i
- søkeresultatet, mens de merket 'bottom' henter fra de 5 siste. En
- kan her se at resultatene påvirkes betydelig av hvorvidt en ser på
- de første eller de siste filmene i et søketreff.
-
-
-  -
-  -
-
-  -
-  -
-
-  -
-  -
-
-  -
-  -
-
-
-
Det er verdt å bemerke at de omtalte bittorrent-katalogene ikke er
- laget for bruk med Popcorn Time. Eksempelvis tilhører katalogen
- YTS, som brukes av klientet som ble lastes ned fra popcorntime.sh,
- et selvstendig fildelings-relatert nettsted YTS.AG med et separat
- brukermiljø. MÃ¥lemetoden foreslÃ¥tt av Ãkokrim mÃ¥ler dermed ikke
- (u)lovligheten rundt bruken av Popcorn Time, men (u)lovligheten til
- innholdet i disse katalogene.
+
+
22nd May 2019
+
This morning, a new release of
+Nikita
+Noark 5 core project was
+announced
+on the project mailing list. The Nikita free software solution is
+an implementation of the Norwegian archive standard Noark 5 used by
+government offices in Norway. These were the changes in version 0.4
+since version 0.3, see the email link above for links to a demo site:
-
+
-Metoden fra Ãkokrims dokument 09,13 i straffesaken
-om DNS-beslag.
+ - Roll out OData handling to all endpoints where applicable
+ - Changed the relation key for "ny-journalpost" to the official one.
+ - Better link generation on outgoing links.
+ - Tidy up code and make code and approaches more consistent throughout
+ the codebase
+ - Update rels to be in compliance with updated version in the
+ interface standard
+ - Avoid printing links on empty objects as they can't have links
+ - Small bug fixes and improvements
+ - Start moving generation of outgoing links to @Service layer so access
+ control can be used when generating links
+ - Log exception that was being swallowed so it's traceable
+ - Fix name mapping problem
+ - Update templated printing so templated should only be printed if it
+ is set true. Requires more work to roll out across entire
+ application.
+ - Remove Record->DocumentObject as per domain model of n5v4
+ - Add ability to delete lists filtered with OData
+ - Return NO_CONTENT (204) on delete as per interface standard
+ - Introduce support for ConstraintViolationException exception
+ - Make Service classes extend NoarkService
+ - Make code base respect X-Forwarded-Host, X-Forwarded-Proto and
+ X-Forwarded-Port
+ - Update CorrespondencePart* code to be more in line with Single
+ Responsibility Principle
+ - Make package name follow directory structure
+ - Make sure Document number starts at 1, not 0
+ - Fix isues discovered by FindBugs
+ - Update from Date to ZonedDateTime
+ - Fix wrong tablename
+ - Introduce Service layer tests
+ - Improvements to CorrespondencePart
+ - Continued work on Class / Classificationsystem
+ - Fix feature where authors were stored as storageLocations
+ - Update HQL builder for OData
+ - Update OData search capability from webpage
+
+
-
1. Evaluation of (il)legality
+
If free and open standardized archiving API sound interesting to
+you, please contact us on IRC
+(#nikita on
+irc.freenode.net) or email
+(nikita-noark
+mailing list).
-
1.1. Methodology
-
-
Due to its technical configuration, Popcorn Time applications don't
-allow to make a full list of all titles made available. In order to
-evaluate the level of illegal operation of PCT, the following
-methodology was applied:
-
-
-
- - A random selection of 50 keywords, greater than 3 letters, was
- made from the Dale-Chall list that contains 3000 simple English
- words1. The selection was made by using a Random Number
- Generator2.
-
- - For each keyword, starting with the first randomly selected
- keyword, a search query was conducted in the movie section of the
- respective Popcorn Time application. For each keyword, the first
- five results were added to the title list until the number of 100
- unique titles was reached (duplicates were removed).
-
- - For one fork, .CH, insufficient titles were generated via this
- approach to reach 100 titles. This was solved by adding any
- additional query results above five for each of the 50 keywords.
- Since this still was not enough, another 42 random keywords were
- selected to finally reach 100 titles.
-
- - It was verified whether or not there is a reasonable expectation
- that the work is copyrighted by checking if they are available on
- IMDb, also verifying the director, the year when the title was
- released, the release date for a certain market, the production
- company/ies of the title and the distribution company/ies.
-
-
-
-
1.2. Results
-
-
Between 6 and 9 June 2016, four forks of Popcorn Time were
-investigated: popcorn-time.to, popcorntime.ag, popcorntime.sh and
-popcorntime.ch. An excel sheet with the results is included in
-Appendix 1. Screenshots were secured in separate Appendixes for each
-respective fork, see Appendix 2-5.
-
-
For each fork, out of 100, de-duplicated titles it was possible to
-retrieve data according to the parameters set out above that indicate
-that the title is commercially available. Per fork, there was 1 title
-that presumably falls within the public domain, i.e. the 1928 movie
-"The Circus" by and with Charles Chaplin.
-
-
Based on the above it is reasonable to assume that 99% of the movie
-content of each fork is copyright protected and is made available
-illegally.
-
-
This exercise was not repeated for TV series, but considering that
-besides production companies and distribution companies also
-broadcasters may have relevant rights, it is reasonable to assume that
-at least a similar level of infringement will be established.
-
-
Based on the above it is reasonable to assume that 99% of all the
-content of each fork is copyright protected and are made available
-illegally.
+
As usual, if you use Bitcoin and want to show your support of my
+activities, please send Bitcoin donations to my address
+15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
@@ -687,43 +300,59 @@ illegally.
-
-
17th December 2017
-
After several months of working and waiting, I am happy to report
-that the nice and user friendly 3D printer slicer software Cura just
-entered Debian Unstable. It consist of five packages,
-cura,
-cura-engine,
-libarcus,
-fdm-materials,
-libsavitar and
-uranium. The last
-two, uranium and cura, entered Unstable yesterday. This should make
-it easier for Debian users to print on at least the Ultimaker class of
-3D printers. My nearest 3D printer is an Ultimaker 2+, so it will
-make life easier for at least me. :)
-
-
The work to make this happen was done by Gregor Riepl, and I was
-happy to assist him in sponsoring the packages. With the introduction
-of Cura, Debian is up to three 3D printer slicers at your service,
-Cura, Slic3r and Slic3r Prusa. If you own or have access to a 3D
-printer, give it a go. :)
-
-
The 3D printer software is maintained by the 3D printer Debian
-team, flocking together on the
-3dprinter-general
-mailing list and the
-#debian-3dprinting
-IRC channel.
-
-
The next step for Cura in Debian is to update the cura package to
-version 3.0.3 and then update the entire set of packages to version
-3.1.0 which showed up the last few days.
+
+
20th May 2019
+
As part of my involvement in the work to
+standardise
+a REST based API for Noark 5, the Norwegian archiving standard, I
+spent some time the last few months to try to register a
+MIME type
+and PRONOM
+code for the SOSI file format. The background is that there is a
+set of formats approved for long term storage and archiving in Norway,
+and among these formats, SOSI is the only format missing a MIME type
+and PRONOM code.
+
+
What is SOSI, you might ask? To quote Wikipedia: SOSI is short for
+Samordnet Opplegg for Stedfestet Informasjon (literally "Coordinated
+Approach for Spatial Information", but more commonly expanded in
+English to Systematic Organization of Spatial Information). It is a
+text based file format for geo-spatial vector information used in
+Norway. Information about the SOSI format can be found in English
+from Wikipedia. The
+specification is available in Norwegian from
+the
+Norwegian mapping authority. The SOSI standard, which originated
+in the beginning of nineteen eighties, was the inspiration and formed the
+basis for the XML based
+Geography
+Markup Language.
+
+
I have so far written
+a pattern matching
+rule for the file(1) unix tool to recognize SOSI files, submitted
+a request to the PRONOM project to have a PRONOM ID assigned to the
+format (reference TNA1555078202S60), and today send a request to IANA
+to register the "text/vnd.sosi" MIME type for this format (referanse
+IANA
+#1143144). If all goes well, in a few months, anyone implementing
+the Noark 5 Tjenestegrensesnitt API spesification should be able to
+use an official MIME type and PRONOM code for SOSI files. In
+addition, anyone using SOSI files on Linux should be able to
+automatically recognise the format and web sites handing out SOSI
+files can begin providing a more specific MIME type. So far, SOSI
+files has been handed out from web sites using the
+"application/octet-stream" MIME type, which is just a nice way of
+stating "I do not know". Soon, we will know. :)
+
+
As usual, if you use Bitcoin and want to show your support of my
+activities, please send Bitcoin donations to my address
+15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
@@ -731,76 +360,146 @@ version 3.0.3 and then update the entire set of packages to version
-
-
13th December 2017
-
While looking at
-the scanned copies
-for the copyright renewal entries for movies published in the USA,
-an idea occurred to me. The number of renewals are so few per year, it
-should be fairly quick to transcribe them all and add references to
-the corresponding IMDB title ID. This would give the (presumably)
-complete list of movies published 28 years earlier that did _not_
-enter the public domain for the transcribed year. By fetching the
-list of USA movies published 28 years earlier and subtract the movies
-with renewals, we should be left with movies registered in IMDB that
-are now in the public domain. For the year 1955 (which is the one I
-have looked at the most), the total number of pages to transcribe is
-21. For the 28 years from 1950 to 1978, it should be in the range
-500-600 pages. It is just a few days of work, and spread among a
-small group of people it should be doable in a few weeks of spare
-time.
-
-
A typical copyright renewal entry look like this (the first one
-listed for 1955):
-
-
- ADAM AND EVIL, a photoplay in seven reels by Metro-Goldwyn-Mayer
- Distribution Corp. (c) 17Aug27; L24293. Loew's Incorporated (PWH);
- 10Jun55; R151558.
-
-
-
The movie title as well as registration and renewal dates are easy
-enough to locate by a program (split on first comma and look for
-DDmmmYY). The rest of the text is not required to find the movie in
-IMDB, but is useful to confirm the correct movie is found. I am not
-quite sure what the L and R numbers mean, but suspect they are
-reference numbers into the archive of the US Copyright Office.
-
-
Tracking down the equivalent IMDB title ID is probably going to be
-a manual task, but given the year it is fairly easy to search for the
-movie title using for example
-http://www.imdb.com/find?q=adam+and+evil+1927&s=all.
-Using this search, I find that the equivalent IMDB title ID for the
-first renewal entry from 1955 is
-http://www.imdb.com/title/tt0017588/.
-
-
I suspect the best way to do this would be to make a specialised
-web service to make it easy for contributors to transcribe and track
-down IMDB title IDs. In the web service, once a entry is transcribed,
-the title and year could be extracted from the text, a search in IMDB
-conducted for the user to pick the equivalent IMDB title ID right
-away. By spreading out the work among volunteers, it would also be
-possible to make at least two persons transcribe the same entries to
-be able to discover any typos introduced. But I will need help to
-make this happen, as I lack the spare time to do all of this on my
-own. If you would like to help, please get in touch. Perhaps you can
-draft a web service for crowd sourcing the task?
-
-
Note, Project Gutenberg already have some
-transcribed
-copies of the US Copyright Office renewal protocols, but I have
-not been able to find any film renewals there, so I suspect they only
-have copies of renewal for written works. I have not been able to find
-any transcribed versions of movie renewals so far. Perhaps they exist
-somewhere?
-
-
I would love to figure out methods for finding all the public
-domain works in other countries too, but it is a lot harder. At least
-for Norway and Great Britain, such work involve tracking down the
-people involved in making the movie and figuring out when they died.
-It is hard enough to figure out who was part of making a movie, but I
-do not know how to automate such procedure without a registry of every
-person involved in making movies and their death year.
+
+
25th March 2019
+
As part of my involvement with the
+Nikita
+Noark 5 core project, I have been proposing improvements to the
+API specification created by The
+National Archives of Norway and helped migrating the text from a
+version control system unfriendly binary format (docx) to Markdown in
+git. Combined with the migration to a public git repository (on
+github), this has made it possible for anyone to suggest improvement
+to the text.
+
+
The specification is filled with UML diagrams. I believe the
+original diagrams were modelled using Sparx Systems Enterprise
+Architect, and exported as EMF files for import into docx. This
+approach make it very hard to track changes using a version control
+system. To improve the situation I have been looking for a good text
+based UML format with associated command line free software tools on
+Linux and Windows, to allow anyone to send in corrections to the UML
+diagrams in the specification. The tool must be text based to work
+with git, and command line to be able to run it automatically to
+generate the diagram images. Finally, it must be free software to
+allow anyone, even those that can not accept a non-free software
+license, to contribute.
+
+
I did not know much about free software UML modelling tools when I
+started. I have used dia and inkscape for simple modelling in the
+past, but neither are available on Windows, as far as I could tell. I
+came across a nice
+list
+of text mode uml tools, and tested out a few of the tools listed
+there. The PlantUML tool seemed
+most promising. After verifying that the packages
+is available in
+Debian and found its
+Java source under a GPL license on github, I set out to test if it
+could represent the diagrams we needed, ie the ones currently in
+the
+Noark 5 Tjenestegrensesnitt specification. I am happy to report
+that it could represent them, even thought it have a few warts here
+and there.
+
+
After a few days of modelling I completed the task this weekend. A
+temporary link to the complete set of diagrams (original and from
+PlantUML) is available in
+the
+github issue discussing the need for a text based UML format, but
+please note I lack a sensible tool to convert EMF files to PNGs, so
+the "original" rendering is not as good as the original was in the
+publised PDF.
+
+
Here is an example UML diagram, showing the core classes for
+keeping metadata about archived documents:
+
+
+@startuml
+skinparam classAttributeIconSize 0
+
+!include media/uml-class-arkivskaper.iuml
+!include media/uml-class-arkiv.iuml
+!include media/uml-class-klassifikasjonssystem.iuml
+!include media/uml-class-klasse.iuml
+!include media/uml-class-arkivdel.iuml
+!include media/uml-class-mappe.iuml
+!include media/uml-class-merknad.iuml
+!include media/uml-class-registrering.iuml
+!include media/uml-class-basisregistrering.iuml
+!include media/uml-class-dokumentbeskrivelse.iuml
+!include media/uml-class-dokumentobjekt.iuml
+!include media/uml-class-konvertering.iuml
+!include media/uml-datatype-elektronisksignatur.iuml
+
+Arkivstruktur.Arkivskaper "+arkivskaper 1..*" <-o "+arkiv 0..*" Arkivstruktur.Arkiv
+Arkivstruktur.Arkiv o--> "+underarkiv 0..*" Arkivstruktur.Arkiv
+Arkivstruktur.Arkiv "+arkiv 1" o--> "+arkivdel 0..*" Arkivstruktur.Arkivdel
+Arkivstruktur.Klassifikasjonssystem "+klassifikasjonssystem [0..1]" <--o "+arkivdel 1..*" Arkivstruktur.Arkivdel
+Arkivstruktur.Klassifikasjonssystem "+klassifikasjonssystem [0..1]" o--> "+klasse 0..*" Arkivstruktur.Klasse
+Arkivstruktur.Arkivdel "+arkivdel 0..1" o--> "+mappe 0..*" Arkivstruktur.Mappe
+Arkivstruktur.Arkivdel "+arkivdel 0..1" o--> "+registrering 0..*" Arkivstruktur.Registrering
+Arkivstruktur.Klasse "+klasse 0..1" o--> "+mappe 0..*" Arkivstruktur.Mappe
+Arkivstruktur.Klasse "+klasse 0..1" o--> "+registrering 0..*" Arkivstruktur.Registrering
+Arkivstruktur.Mappe --> "+undermappe 0..*" Arkivstruktur.Mappe
+Arkivstruktur.Mappe "+mappe 0..1" o--> "+registrering 0..*" Arkivstruktur.Registrering
+Arkivstruktur.Merknad "+merknad 0..*" <--* Arkivstruktur.Mappe
+Arkivstruktur.Merknad "+merknad 0..*" <--* Arkivstruktur.Dokumentbeskrivelse
+Arkivstruktur.Basisregistrering -|> Arkivstruktur.Registrering
+Arkivstruktur.Merknad "+merknad 0..*" <--* Arkivstruktur.Basisregistrering
+Arkivstruktur.Registrering "+registrering 1..*" o--> "+dokumentbeskrivelse 0..*" Arkivstruktur.Dokumentbeskrivelse
+Arkivstruktur.Dokumentbeskrivelse "+dokumentbeskrivelse 1" o-> "+dokumentobjekt 0..*" Arkivstruktur.Dokumentobjekt
+Arkivstruktur.Dokumentobjekt *-> "+konvertering 0..*" Arkivstruktur.Konvertering
+Arkivstruktur.ElektroniskSignatur -[hidden]-> Arkivstruktur.Dokumentobjekt
+@enduml
+
+
+
The format is quite
+compact, with little redundant information. The text expresses
+entities and relations, and there is little layout related fluff. One
+can reuse content by using include files, allowing for consistent
+naming across several diagrams. The include files can be standalone
+PlantUML too. Here is the content of
+media/uml-class-arkivskaper.iuml:
+
+
+@startuml
+class Arkivstruktur.Arkivskaper {
+ +arkivskaperID : string
+ +arkivskaperNavn : string
+ +beskrivelse : string [0..1]
+}
+@enduml
+
+
+
This is what the complete diagram for the PlantUML notation above
+look like:
+
+
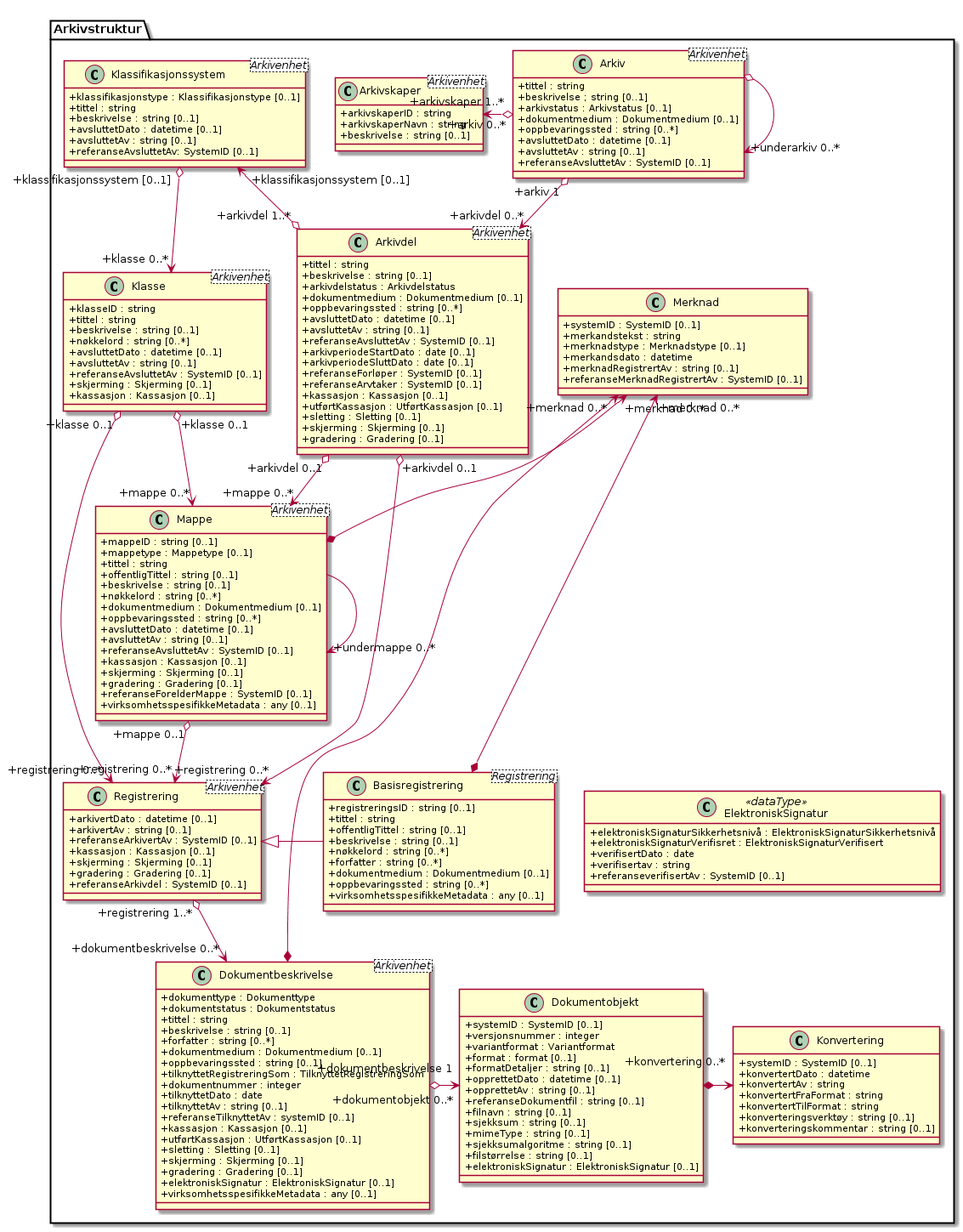
+
+
A cool feature of PlantUML is that the generated PNG files include
+the entire original source diagram as text. The source (with include
+statements expanded) can be extracted using for example
+exiftool. Another cool feature is that parts of the entities
+can be hidden after inclusion. This allow to use include files with
+all attributes listed, even for UML diagrams that should not list any
+attributes.
+
+
The diagram also show some of the warts. Some times the layout
+engine place text labels on top of each other, and some times it place
+the class boxes too close to each other, not leaving room for the
+labels on the relationship arrows. The former can be worked around by
+placing extra newlines in the labes (ie "\n"). I did not do it here
+to be able to demonstrate the issue. I have not found a good way
+around the latter, so I normally try to reduce the problem by changing
+from vertical to horizontal links to improve the layout.
+
+
All in all, I am quite happy with PlantUML, and very impressed with
+how quickly its lead developer responds to questions. So far I got an
+answer to my questions in a few hours when I send an email. I
+definitely recommend looking at PlantUML if you need to make UML
+diagrams. Note, PlantUML can draw a lot more than class relations.
+Check out the documention for a complete list. :)
As usual, if you use Bitcoin and want to show your support of my
activities, please send Bitcoin donations to my address
@@ -809,7 +508,7 @@ activities, please send Bitcoin donations to my address
@@ -817,40 +516,47 @@ activities, please send Bitcoin donations to my address
-
-
5th December 2017
-
Three years ago, a presumed lost animation film,
-Empty Socks from
-1927, was discovered in the Norwegian National Library. At the
-time it was discovered, it was generally assumed to be copyrighted by
-The Walt Disney Company, and I blogged about
-my
-reasoning to conclude that it would would enter the Norwegian
-equivalent of the public domain in 2053, based on my understanding of
-Norwegian Copyright Law. But a few days ago, I came across
-a
-blog post claiming the movie was already in the public domain, at
-least in USA. The reasoning is as follows: The film was released in
-November or Desember 1927 (sources disagree), and presumably
-registered its copyright that year. At that time, right holders of
-movies registered by the copyright office received government
-protection for there work for 28 years. After 28 years, the copyright
-had to be renewed if the wanted the government to protect it further.
-The blog post I found claim such renewal did not happen for this
-movie, and thus it entered the public domain in 1956. Yet someone
-claim the copyright was renewed and the movie is still copyright
-protected. Can anyone help me to figure out which claim is correct?
-I have not been able to find Empty Socks in Catalog of copyright
-entries. Ser.3 pt.12-13 v.9-12 1955-1958 Motion Pictures
-available
-from the University of Pennsylvania, neither in
-page
-45 for the first half of 1955, nor in
-page
-119 for the second half of 1955. It is of course possible that
-the renewal entry was left out of the printed catalog by mistake. Is
-there some way to rule out this possibility? Please help, and update
-the wikipedia page with your findings.
+
+
24th March 2019
+
Yesterday, a new release of
+Nikita
+Noark 5 core project was
+announced
+on the project mailing list. The free software solution is an
+implementation of the Norwegian archive standard Noark 5 used by
+government offices in Norway. These were the changes in version 0.3
+since version 0.2.1 (from NEWS.md):
+
+
+ - Improved ClassificationSystem and Class behaviour.
+ - Tidied up known inconsistencies between domain model and hateaos links.
+ - Added experimental code for blockchain integration.
+ - Make token expiry time configurable at upstart from properties file.
+ - Continued work on OData search syntax.
+ - Started work on pagination for entities, partly implemented for Saksmappe.
+ - Finalise ClassifiedCode Metadata entity.
+ - Implement mechanism to check if authentication token is still
+ valid. This allow the GUI to return a more sensible message to the
+ user if the token is expired.
+ - Reintroduce browse.html page to allow user to browse JSON API using
+ hateoas links.
+ - Fix bug in handling file/mappe sequence number. Year change was
+ not properly handled.
+ - Update application yml files to be in sync with current development.
+ - Stop 'converting' everything to PDF using libreoffice. Only
+ convert the file formats doc, ppt, xls, docx, pptx, xlsx, odt, odp
+ and ods.
+ - Continued code style fixing, making code more readable.
+ - Minor bug fixes.
+
+
+
+
If free and open standardized archiving API sound interesting to
+you, please contact us on IRC
+(#nikita on
+irc.freenode.net) or email
+(nikita-noark
+mailing list).
As usual, if you use Bitcoin and want to show your support of my
activities, please send Bitcoin donations to my address
@@ -859,7 +565,7 @@ activities, please send Bitcoin donations to my address
@@ -867,124 +573,183 @@ activities, please send Bitcoin donations to my address
-
-
28th November 2017
-
It would be easier to locate the movie you want to watch in
-the Internet Archive, if the
-metadata about each movie was more complete and accurate. In the
-archiving community, a well known saying state that good metadata is a
-love letter to the future. The metadata in the Internet Archive could
-use a face lift for the future to love us back. Here is a proposal
-for a small improvement that would make the metadata more useful
-today. I've been unable to find any document describing the various
-standard fields available when uploading videos to the archive, so
-this proposal is based on my best quess and searching through several
-of the existing movies.
-
-
I have a few use cases in mind. First of all, I would like to be
-able to count the number of distinct movies in the Internet Archive,
-without duplicates. I would further like to identify the IMDB title
-ID of the movies in the Internet Archive, to be able to look up a IMDB
-title ID and know if I can fetch the video from there and share it
-with my friends.
-
-
Second, I would like the Butter data provider for The Internet
-archive
-(available
-from github), to list as many of the good movies as possible. The
-plugin currently do a search in the archive with the following
-parameters:
-
-
-collection:moviesandfilms
-AND NOT collection:movie_trailers
-AND -mediatype:collection
-AND format:"Archive BitTorrent"
-AND year
-
-
-
Most of the cool movies that fail to show up in Butter do so
-because the 'year' field is missing. The 'year' field is populated by
-the year part from the 'date' field, and should be when the movie was
-released (date or year). Two such examples are
-Ben Hur
-from 1905 and
-Caminandes
-2: Gran Dillama from 2013, where the year metadata field is
-missing.
-
-So, my proposal is simply, for every movie in The Internet Archive
-where an IMDB title ID exist, please fill in these metadata fields
-(note, they can be updated also long after the video was uploaded, but
-as far as I can tell, only by the uploader):
-
-
-
-- mediatype
-- Should be 'movie' for movies.
-
-- collection
-- Should contain 'moviesandfilms'.
-
-- title
-- The title of the movie, without the publication year.
-
-- date
-- The data or year the movie was released. This make the movie show
-up in Butter, as well as make it possible to know the age of the
-movie and is useful to figure out copyright status.
-
-- director
-- The director of the movie. This make it easier to know if the
-correct movie is found in movie databases.
-
-- publisher
-- The production company making the movie. Also useful for
-identifying the correct movie.
-
-- links
-
-- Add a link to the IMDB title page, for example like this: <a
-href="http://www.imdb.com/title/tt0028496/">Movie in
-IMDB</a>. This make it easier to find duplicates and allow for
-counting of number of unique movies in the Archive. Other external
-references, like to TMDB, could be added like this too.
-
-
-
-
I did consider proposing a Custom field for the IMDB title ID (for
-example 'imdb_title_url', 'imdb_code' or simply 'imdb', but suspect it
-will be easier to simply place it in the links free text field.
-
-
I created
-a
-list of IMDB title IDs for several thousand movies in the Internet
-Archive, but I also got a list of several thousand movies without
-such IMDB title ID (and quite a few duplicates). It would be great if
-this data set could be integrated into the Internet Archive metadata
-to be available for everyone in the future, but with the current
-policy of leaving metadata editing to the uploaders, it will take a
-while before this happen. If you have uploaded movies into the
-Internet Archive, you can help. Please consider following my proposal
-above for your movies, to ensure that movie is properly
-counted. :)
-
-
The list is mostly generated using wikidata, which based on
-Wikipedia articles make it possible to link between IMDB and movies in
-the Internet Archive. But there are lots of movies without a
-Wikipedia article, and some movies where only a collection page exist
-(like for the
-Caminandes example above, where there are three movies but only
-one Wikidata entry).
-
-
As usual, if you use Bitcoin and want to show your support of my
-activities, please send Bitcoin donations to my address
-15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
+
+
11th March 2019
+
Et virksomhetsarkiv for meg, er et arbeidsverktøy der en enkelt kan
+finne informasjonen en trenger når en trenger det, og der
+virksomhetens samlede kunnskap er tilgjengelig. Det må være greit å
+finne frem i, litt som en bibliotek. Men der et bibliotek gjerne tar
+vare på offentliggjort informasjon som er tilgjengelig flere steder,
+tar et arkiv vare på virksomhetsintern og til tider personlig
+informasjon som ofte kun er tilgjengelig fra et sted.
+
+
Jeg mistenker den eneste måten å sikre at arkivet inneholder den
+samlede kunnskapen i en virksomhet, er å bruke det som virksomhetens
+kunnskapslager. Det innebærer å automatisk kopiere (brev, epost,
+SMS-er etc) inn i arkivet når de sendes og mottas, og der filtrere
+vekk det en ikke vil ta vare på, og legge på metadata om det som er
+samlet inn for enkel gjenfinning. En slik bruk av arkivet innebærer at
+arkivet er en del av daglig virke, ikke at det er siste hvilested for
+informasjon ingen lenger har daglig bruk for. For å kunne være en del
+av det daglige virket må arkivet enkelt kunne integreres med andre
+systemer. I disse dager betyr det å tilby arkivet som en
+nett-tjeneste til hele virksomheten, tilgjengelig for både mennesker
+og datamaskiner. Det betyr i tur å både tilby nettsider og et
+maskinlesbart grensesnitt.
+
+
For noen år siden erkjente visjonære arkivarer fordelene med et
+standardisert maskinlesbart grensesnitt til organisasjonens arkiv. De
+gikk igang med å lage noe de kalte
+Noark
+5 Tjenestegrensesnitt. Gjort riktig, så åpner slike maskinlesbare
+grensesnitt for samvirke på tvers av uavhengige programvaresystemer.
+Gjort feil, vil det blokkere for samvirke og bidra til
+leverandørinnlåsing. For å gjøre det riktig så må grensesnittet være
+klart og entydig beskrevet i en spesifikasjon som gjør at
+spesifikasjonen tolkes på samme måte uavhengig av hvem som leser den,
+og uavhengig av hvem som tar den i bruk.
+
+
For å oppnå klare og entydige beskrivelser i en spesifikasjon, som
+trengs for å kunne få en fri og åpen standard (se
+Digistan-definisjon),
+så trengs det en åpen og gjennomsiktig inngangsport med lav terskel,
+der de som forsøker å ta den i bruk enkelt kan få inn korreksjoner,
+etterlyse klargjøringer og rapportere uklarheter i spesifikasjonen.
+En trenger også automatiserte datasystemer som måler og sjekker at et
+gitt grensesnitt fungerer i tråd med spesifikasjonen.
+
+
For Noark 5 Tjenestegrensesnittet er det nå etablert en slik åpen
+og gjennomsiktig inngangsport på prosjekttjenesten github. Denne
+inngangsporten består først og fremst av en åpen portal som lar enhver
+se hva som er gjort av endringer i spesifikasjonsteksten over tid, men
+det hører også med et åpent "diskusjonsforum" der en kan
+komme med endringsforslag og forespørsler om klargjøringer. Alle
+registrerte brukere på github kan bidra med innspill til disse
+henvendelsene.
+
+
I samarbeide med Arkivverket har jeg fått opprettet et git-depot
+med spesifikasjonsteksten for tjenestegrensesnittet, der det er lagt
+inn historikk for endringer i teksten de siste årene, samt lagt inn
+endringsforslag og forespørsler om klargjøring av teksten. Bakgrunnen
+for at jeg bidro med dette er at jeg er involvert i
+Nikita-prosjektet,
+som lager en fri programvare-utgave av Noark 5 Tjenestegrensesnitt.
+Det er først når en forsøker å lage noe i tråd med en spesifikasjon at
+en oppdager hvor mange detaljer som må beskrives i spesifikasjonen for
+Ã¥ sikre samhandling.
+
+
Spesifikasjonen vedlikeholdes i et rent tekstformat, for å ha et
+format egnet for versjonskontroll via versjontrollsystemet git. Dette
+gjør det både enkelt å se konkret hvilke endringer som er gjort når,
+samt gjør det praktisk mulig for enhver med github-konto å sende inn
+endringsforslag med formuleringer til spesifikasjonsteksten. Dette
+tekstformatet vises frem som nettsider på github, slik at en ikke
+trenger spesielle verktøy for å se på siste utgave av
+spesifikasjonen.
+
+
Fra dette rene tekstformatet kan det så avledes ulike formater, som
+HTML for websider, PDF for utskrift på papir og ePub for lesing med
+ebokleser. Avlednings-systemet (byggesystemet) bruker i dag
+verktøyene pandoc, latex, docbook-xsl og GNU make til
+transformasjonen. Tekstformatet som brukes dag er
+Markdown, men det vurderes
+Ã¥
+endre
+til formatet RST i fremtiden for bedre styring av utseende på
+PDF-utgaven.
+
+
Versjonskontrollsystemet git ble valgt da det er både fleksibelt,
+avansert og enkelt å ta i bruk. Github ble valgt (foran f.eks. Gitlab
+som vi bruker i Nikita), da Arkivverket allerede hadde tatt i bruk
+Github i andre sammenhenger.
+
+
Enkle endringer i teksten kan gjøres av priviligerte brukere
+direkte i nettsidene til Github, ved å finne aktuell fil som skal
+endres (f.eks. kapitler/03-konformitet.md), klikke på den lille
+bokstaven i høyre hjørne over teksten. Det kommer opp en nettside der
+en kan endre teksten slik en ønsker. Når en er fornøyd med endringen
+så må endringen "sjekkes inn" i historikken. Det gjøres ved
+Ã¥ gi en kort beskrivelse av endringen (beskriv helst hvorfor endringen
+trengs, ikke hva som er endret), under overskriften "Commit
+changes". En kan og bør legge inn en lengre forklaring i det
+større skrivefeltet, før en velger om endringen skal sendes direkte
+til 'master'-grenen (dvs. autorativ utgave av spesifikasjonen) eller
+om en skal lage en ny gren for denne endringen og opprette en
+endringsforespørsel (aka "Pull Request"/PR). Når alt dette
+er gjort kan en velge "Commit changes" for å sende inn
+endringen. Hvis den er lagt inn i "master"-grenen så er den
+en offisiell del av spesifikasjonen med en gang. Hvis den derimot er
+en endringsforespørsel, så legges den inn i
+listen
+over forslag til endringer som venter på korrekturlesing og
+godkjenning.
+
+
Større endringer (for eksempel samtidig endringer i flere filer)
+gjøres enklest ved å hente ned en kopi av git-depoet lokalt og gjøre
+endringene der før endringsforslaget sendes inn. Denne prosessen er
+godt beskrivet i dokumentasjon fra github. Git-prosjektet som skal
+"klones" er
+https://github.com/arkivverket/noark5-tjenestegrensesnitt-standard/.
+
+
For å registrere nye utfordringer (issues) eller kommentere på
+eksisterende utfordringer benyttes nettsiden
+https://github.com/arkivverket/noark5-tjenestegrensesnitt-standard/issues.
+I skrivende stund er det 48 åpne og 11 avsluttede utfordringer. Et
+forslag til hva som bør være med når en beskriver en utfordring er
+tilgjengelig som utfordring
+#14.
+
+
For å bygge en PDF-utgave av spesifikasjonen så bruker jeg i dag en
+Debian GNU/Linux-maskin med en rekke programpakker installert. NÃ¥r
+dette er på plass, så holder det å kjøre kommandoen 'make pdf html' på
+kommandolinjen, vente ca. 20 sekunder, før spesifikasjon.pdf og
+spesifikasjon.html ligger klar på disken. Verktøyene for bygging av
+PDF, HTML og ePub-utgave er også tilgjengelig på Windows og
+MacOSX.
+
+
Github bidrar med rammeverket. Men for at åpent vedlikehold av
+spesifikasjonen skal fungere, så trengs det folk som bidrar med sin
+tid og kunnskap. Arkivverket har sagt de skal bidra med innspill og
+godkjenne forslag til endringer, men det blir størst suksess hvis alle
+som bruker og lager systemer basert på Noark 5 Tjenestegrensesnitt
+bidrar med sin kunnskap og kommer med forslag til forebedringer. Jeg
+stiller. Blir du med?
+
+
Det er viktig å legge til rette for åpen diskusjon blant alle
+interesserte, som ikke krever at en må godta lange kontrakter med
+vilkår for deltagelse. Inntil Arkivverket dukker opp på IRC har vi
+laget en IRC-kanal der interesserte enkelt kan orientere seg og
+diskutere tjenestegrensesnittet. Alle er velkommen til å ta turen
+innom
+#nikita
+(f.eks. via irc.freenode.net) for å møte likesinnede.
+
+
Det holder dog ikke å ha en god spesifikasjon, hvis ikke de som tar
+den i bruk gjør en like god jobb. For å automatisk teste om et konkret
+tjenestegrensesnitt følger (min) forståelse av
+spesifikasjonsdokumentet, har jeg skrevet et program som kobler seg
+opp til et Noark 5v4 REST-tjeneste og tester alt den finner for å se
+om det er i henhold til min tolkning av spesifikasjonen. Dette
+verktøyet er tilgjengelig fra
+https://github.com/petterreinholdtsen/noark5-tester,
+og brukes daglig mens vi utvikler Nikita for å sikre at vi ikke
+introduserer nye feil. Hvis en skal sikre samvirke på tvers av ulike
+systemer er det helt essensielt å kunne raskt og automatisk sjekke at
+tjenestegrensesnittet oppfører seg som forventet. Jeg håper andre som
+lager sin utgave av tjenestegrensesnittet vi bruke dette verktøyet,
+slik at vi tidlig og raskt kan oppdage hvor vi har tolket
+spesifikasjonen ulikt, og dermed få et godt grunnlag for å gjøre
+spesifikasjonsteksten enda klarere og bedre.
+
+
Dagens beskrivelse av Noark 5 Tjenestegrensesnitt er et svært godt
+utgangspunkt for å gjøre virksomhetens arkiv til et dynamisk og
+sentralt arbeidsverktøy i organisasjonen. Blir du med å gjøre den
+enda bedre?
@@ -992,76 +757,100 @@ activities, please send Bitcoin donations to my address
-
-
18th November 2017
-
A month ago, I blogged about my work to
-automatically
-check the copyright status of IMDB entries, and try to count the
-number of movies listed in IMDB that is legal to distribute on the
-Internet. I have continued to look for good data sources, and
-identified a few more. The code used to extract information from
-various data sources is available in
-a
-git repository, currently available from github.
-
-
So far I have identified 3186 unique IMDB title IDs. To gain
-better understanding of the structure of the data set, I created a
-histogram of the year associated with each movie (typically release
-year). It is interesting to notice where the peaks and dips in the
-graph are located. I wonder why they are placed there. I suspect
-World War II caused the dip around 1940, but what caused the peak
-around 2010?
-
-
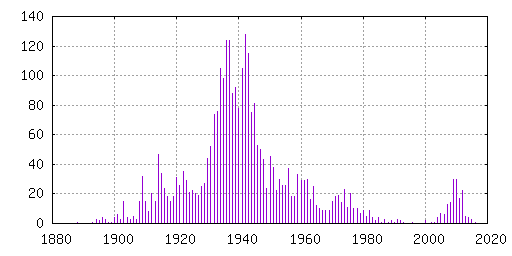
-
-
I've so far identified ten sources for IMDB title IDs for movies in
-the public domain or with a free license. This is the statistics
-reported when running 'make stats' in the git repository:
+
+
13th February 2019
+
For
+syv år siden oppdaget jeg at billettautomater for
+kollektivtrafikken i Oslo kjørte
+Windows 2000
+Professional. Operativsystemet har ikke fått sikkerhetsfikser fra
+Microsoft siden 2010-07-13 i følge dem selv. Den samme versjonen av
+operativsystemet var i bruk
+for
+to og et halvt år siden, og jammen er det ikke også i bruk den dag
+i dag:
+
+
![[Bilde av Ruters billettautomat med Windows 2000-feilmelding]](http://people.skolelinux.org/pere/blog/images/2019-02-13-ruter-win2000pro.jpeg)
+
+
Bildet er tatt i dag av Kirill Miazine og tilgjengelig for bruk med
+bruksvilkårene til
+Creative
+Commons Attribution 4.0 International (CC BY 4.0).
+
+
Kanskje det hadde vært
+bedre
+med gratis kollektivtrafikk, slik at vi slapp å stole på
+datakompetansen til Ruter for å verne våre privatliv samt holde
+personopplysninger og betalingsinformasjon unna uvedkommende. Eneste
+måten å sikre at hvor en befinner seg ikke kan hentes ut fra Ruters
+systemer er å betale enkeltbilletter med kontanter. Jeg vet at Ruter
+har en god historie om hvor personvernvennlige mobil-app og
+RFID-kortene er, men den historien er ikke mulig å uavhengig
+kontrollere uten priviligert tilgang til interne system og blir dermed
+bare nok en god historie basert på tillit til de som forteller
+historien. Det er ikke slik en sikrer privatsfæren. Det gjør en ved
+Ã¥ sikre at det ikke (kan) registreres informasjon om ens person.
-
- 249 entries ( 6 unique) with and 288 without IMDB title ID in free-movies-archive-org-butter.json
- 2301 entries ( 540 unique) with and 0 without IMDB title ID in free-movies-archive-org-wikidata.json
- 830 entries ( 29 unique) with and 0 without IMDB title ID in free-movies-icheckmovies-archive-mochard.json
- 2109 entries ( 377 unique) with and 0 without IMDB title ID in free-movies-imdb-pd.json
- 291 entries ( 122 unique) with and 0 without IMDB title ID in free-movies-letterboxd-pd.json
- 144 entries ( 135 unique) with and 0 without IMDB title ID in free-movies-manual.json
- 350 entries ( 1 unique) with and 801 without IMDB title ID in free-movies-publicdomainmovies.json
- 4 entries ( 0 unique) with and 124 without IMDB title ID in free-movies-publicdomainreview.json
- 698 entries ( 119 unique) with and 118 without IMDB title ID in free-movies-publicdomaintorrents.json
- 8 entries ( 8 unique) with and 196 without IMDB title ID in free-movies-vodo.json
- 3186 unique IMDB title IDs in total
-
-
-
The entries without IMDB title ID are candidates to increase the
-data set, but might equally well be duplicates of entries already
-listed with IMDB title ID in one of the other sources, or represent
-movies that lack a IMDB title ID. I've seen examples of all these
-situations when peeking at the entries without IMDB title ID. Based
-on these data sources, the lower bound for movies listed in IMDB that
-are legal to distribute on the Internet is between 3186 and 4713.
-
-
It would be great for improving the accuracy of this measurement,
-if the various sources added IMDB title ID to their metadata. I have
-tried to reach the people behind the various sources to ask if they
-are interested in doing this, without any replies so far. Perhaps you
-can help me get in touch with the people behind VODO, Public Domain
-Torrents, Public Domain Movies and Public Domain Review to try to
-convince them to add more metadata to their movie entries?
-
-
Another way you could help is by adding pages to Wikipedia about
-movies that are legal to distribute on the Internet. If such page
-exist and include a link to both IMDB and The Internet Archive, the
-script used to generate free-movies-archive-org-wikidata.json should
-pick up the mapping as soon as wikidata is updates.
+
Som vanlig, hvis du bruker Bitcoin og ønsker å vise din støtte til
+det jeg driver med, setter jeg pris på om du sender Bitcoin-donasjoner
+til min adresse
+15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
+Merk, betaling med bitcoin er ikke anonymt. :)
+
+
+
+
+
+
+
+
7th February 2019
+
Jeg registrerer med glede at Stortinget i dag har
+vedtatt
+at det skal vedlikeholdes et åpent og maskinlesbart register over
+reelle rettighetshavere i Norge. Her kan en kanskje få et
+register som kan brukes til å analysere eierskap og kontroll i Norge
+maskinelt og knytte det til internasjonale databaser som
+OpenCorporates. Det liker
+jeg.
+
+
Den vedtatte grense på 25 prosents eierandel fikk stor
+oppmerksomhet i debatten. Jeg ser fra enkel analyse av skatteetatens
+eierskapsregister at 80.4% av alle selskapseiere i registeret har
+mindre enn 25% eierandel, mot 73.8% som har mindre enn 5% eierandel.
+En grense på 25% vil altså utelukke 80.4% av selskapseierne fra det
+vedtatte registeret, og en grense på 5% vil skjule 73.8%. En må helt
+ned i registrering av eierandeler over circa 0.002% for å få mer enn
+halvparten av selskapseierne i Norge. Mon tro hvor langt ned en må i
+eierprosent for å få med alle eierskapene til politisk valgte
+representanter?
+
+
Jeg biter meg også merke i at Sivert Bjørnstad fra FrP
+tilsynelatende tror at aksjonærregisteret er et eksisterende åpent
+register, på tross av at det så vidt jeg vet kun deles ved personlig
+oppmøte hos skatteetaten og ikke er tilgjengelig i maskinlesbart
+format for enhver, og dermed så langt ikke er importert inn i
+OpenCorporates. Det anser jeg ikke for et spesielt åpent register.
+Debatten ga ellers lite håp om at situasjonen bedrer seg, da
+finansministeren bare henviste til en fraværende næringsministeren og
+ikke ville uttale seg om et skikkelig aksjonærregister snart dukker
+opp.
-
As usual, if you use Bitcoin and want to show your support of my
-activities, please send Bitcoin donations to my address
-15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
+
Som vanlig, hvis du bruker Bitcoin og ønsker å vise din støtte til
+det jeg driver med, setter jeg pris på om du sender Bitcoin-donasjoner
+til min adresse
+15oWEoG9dUPovwmUL9KWAnYRtNJEkP1u1b.
+Merk, betaling med bitcoin er ikke anonymt. :)
@@ -1076,12 +865,45 @@ activities, please send Bitcoin donations to my address
Archive
+- 2019
+
+
- 2018
@@ -1368,47 +1190,51 @@ activities, please send Bitcoin donations to my address
- bankid (4)
- - bitcoin (9)
+ - betalkontant (8)
- - bootsystem (16)
+ - bitcoin (11)
+
+ - bootsystem (17)
- bsa (2)
- chrpath (2)
- - debian (156)
+ - debian (167)
- debian edu (158)
- debian-handbook (4)
- - digistan (10)
+ - digistan (11)
- dld (17)
- - docbook (24)
+ - docbook (26)
- drivstoffpriser (4)
- - english (366)
+ - english (405)
- fiksgatami (23)
- - fildeling (13)
+ - fildeling (14)
- - freeculture (32)
+ - freeculture (34)
- freedombox (9)
- - frikanalen (18)
+ - frikanalen (20)
- h264 (20)
- intervju (42)
- - isenkram (15)
+ - isenkram (16)
+
+ - kart (22)
- - kart (20)
+ - kodi (4)
- ldap (9)
@@ -1422,21 +1248,23 @@ activities, please send Bitcoin donations to my address
- mesh network (8)
- - multimedia (39)
+ - multimedia (42)
+
+ - nice free software (12)
- - nice free software (9)
+ - noark5 (15)
- - norsk (295)
+ - norsk (305)
- - nuug (190)
+ - nuug (195)
- - offentlig innsyn (33)
+ - offentlig innsyn (37)
- open311 (2)
- - opphavsrett (71)
+ - opphavsrett (73)
- - personvern (104)
+ - personvern (108)
- raid (2)
@@ -1446,27 +1274,27 @@ activities, please send Bitcoin donations to my address
- rfid (3)
- - robot (10)
+ - robot (12)
- rss (1)
- - ruter (5)
+ - ruter (7)
- scraperwiki (2)
- - sikkerhet (53)
+ - sikkerhet (55)
- sitesummary (4)
- skepsis (5)
- - standard (55)
+ - standard (64)
- stavekontroll (6)
- stortinget (12)
- - surveillance (53)
+ - surveillance (55)
- sysadmin (4)
@@ -1474,13 +1302,13 @@ activities, please send Bitcoin donations to my address
- valg (9)
- - verkidetfri (10)
+ - verkidetfri (15)
- - video (61)
+ - video (73)
- vitenskap (4)
- - web (40)
+ - web (42)
 -
-
-
- +
+ +
+ +
+
+
+ +
+
+
+